Inhaltsverzeichnis
1 Was ist Multikollinearität?
Multikollinearität kann bei der multiplen linearen Regression auftreten. Sie beschreibt eine zu hohe Korrelation von zwei oder mehr erklärenden Variablen (x-Variablen) miteinander. Ist dem so, könnte man inhaltlich die Frage stellen, ob zwei miteinander hoch korrelierte unabhängige Variablen nicht sogar dasselbe messen. Ein Weglassen einer der beiden Variablen wäre demnach denkbar.
2 Was hat Multikollinearität für Folgen?
Die Regressionskoeffizienten werden im Falle vorliegender Multikollinearität verzerrt geschätzt. Die übliche Interpretation eines Regressionskoeffizienten ist, dass er eine Schätzung des Effekts einer Änderung um eine Einheit der unabhängigen Variablen x1 auf die abhängige Variable y liefert, wobei die anderen unabhängigen Variablen konstant gehalten werden. Wenn x1 in hohem Maße mit einer anderen unabhängigen Variablen x2 korreliert ist, kann eine Konstanthaltung von x2 eben gerade nicht gelingen, um den Effekt der Änderung von x1 um eine Einheit zu schätzen. Ein weiteres Problem können nach oben verzerrte Standardfehler der Koeffizienten sein. Das hat zur Folge, dass der p-Wert verzerrt ist. Das kann wiederum dazu führen, dass die Nullhypothese fälschlicherweise beibehalten wird (Fehler 2. Art).
3 Prüfung auf Multikollinearität mit R
Für einen Teil der Prüfungen muss das Modell bereits gerechnet sein. Daher hier für den Kontext dieser Prüfung, die Modellspezifikation:
- abhängige Variable: Abiturschnitt (Noten sind ordinal, ein Notenschnitt idR metrisch)
- 4 unabhängige Variablen: IQ (metrisch), Motivation (ordinal), Anzahl Akademiker im Haushalt (metrisch), Geschlecht (dichotom)
all:
lm(formula = Abischni ~ IQ + Motivation + Akademikerhaushalt +
Geschlecht, data = data_xls)
Residuals:
Min 1Q Median 3Q Max
-0.52176 -0.13777 0.01036 0.14183 0.52218
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.485742 0.368203 20.330 < 2e-16 ***
IQ -0.036778 0.004194 -8.769 2.23e-11 ***
Motivation -0.130056 0.024024 -5.414 2.17e-06 ***
Akademikerhaushalt -0.159431 0.057025 -2.796 0.00753 **
Geschlecht -0.134621 0.074961 -1.796 0.07908 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.2581 on 46 degrees of freedom
Multiple R-squared: 0.9164, Adjusted R-squared: 0.9092
F-statistic: 126.1 on 4 and 46 DF, p-value: < 2.2e-16
Die Interpretation ist hierbei zweitrangig. Nur so viel: Das Modell leistet mit F(4,46) = 126,1 und p < 0,001 einen signifikanten Erklärungsbeitrag. R² = 91,64% der Varianz der abhängigen Variable werden erklärt. Bei Alpha=5% üben bis auf Geschlecht alle Koeffizienten einen signifikanten negativen Einfluss auf den Abiturschnitt aus.
3.1 Analytische Prüfung
3.1.1 Korrelationsmatrix
Wie eingangs bereits gesagt, kann eine Korrelationsmatrix bereits vor der Modellrechnung durchgeführt werden. Hierzu korreliert man einfach alle unabhängigen Variablen paarweise miteinander.
Am einfachsten funktioniert dies mit der vorherigen Erstellung eines subsets aus meinem Dataframe "data_xls". Das Subset enthält nur die entsprechenden (hier 4) unabhängigen Variablen:
subset_cor <- subset(data_xls, select = c(IQ, Motivation, Akademikerhaushalt, Geschlecht))
In subset_cor sind nun die Variablen, die korreliert werden müssen. Mit der cor()-Funktion kann man eine Korrelationsmatrix (z.B. "korr_tab") erstellen lassen. Mit method="pearson" gebe ich das Argument mit, dass der Pearson-Korrelationskoeffizient berechnet werden soll. Da ich nur metrische und eine dichotome Variable habe, ist dies ok. Dichotome Variablen werden bei Pearson automatisch punktbiserial korreliert.
korr_tab <- cor(subset_cor, method = "pearson") korr_tab
Als Output erhalte ich hieraus:
IQ Motivation Akademikerhaushalt Geschlecht IQ 1.0000000 0.7483621 0.4674192 -0.1027014 Motivation 0.7483621 1.0000000 0.5212433 -0.2346500 Akademikerhaushalt 0.4674192 0.5212433 1.0000000 -0.1526380 Geschlecht -0.1027014 -0.2346500 -0.1526380 1.0000000
In diesem Output ist erkennbar, dass keine wirklich bedenklichen Korrelation vorliegen. Die höchste Korrelation ist 0,748 zwischen Motivation und IQ. Laut Field, A (2018), S. 402 sind Korrelationswerte über 0,8 ein Anzeichen für Multikollinearität. Sollten also zwei unabhängige Variablen mit 0,8 bzw. -0,8 oder mehr miteinander korrelieren, sollte man sich Gedanken darüber machen, eine der beiden aus der Analyse auszuschließen.
3.1.2 VIF-Werte und Toleranz
Relativ unspektakulär und sehr schnell berechenbar sind die sog. VIF-Werte und die Toleranz. VIF heißt "Variance Inflation Factor" und beschreibt in einer Zahl ausgedrückt, wie sehr die unabhängige Variable für Multikollinearität verantwortlich ist und baut auf dem multiplen Korrelationskoeffizient des jeweiligen Prädiktors auf:
![\[ {VIF} _{i}={\frac {1}{1-R_{i}^{2}}}}\]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-43155a89cfb718c41272524751faa870_l3.png "Rendered by QuickLaTeX.com")
Teilt man 1 durch den VIF-Wert, erhält man die Toleranz.
![\[ Toleranz={\frac {1}{VIF_{i}}}}\]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-9ab658972ca47210dcdd6c57caf99b31_l3.png "Rendered by QuickLaTeX.com")
Der Bezug auf eine der beiden Kenngrößen reicht. Ich beschränke mich hier auf VIF-Werte. In R verwendet man dazu das sog. car-Paket und die vif()-Funktion aus ihm. In die vif()-Funktion wird das vorher definierte Modell eingefügt, also dessen Modellname. In meinem Fall (s.o.) heißt es schlicht "model":
install.packages("car")
library(car)
vif(model)
1/vif(model)
Als Output erhält man die VIF-Werte (Toleranz habe ich weggelassen):
IQ Motivation Akademikerhaushalt Geschlecht
2.349620 2.606171 1.403087 1.074974
Hier ist die Faustregel, dass Werte über 10 ein Anzeichen für Multikollinearität sind. Der Vorteil der VIF-Werte im Vergleich mit den reinen Korrelationswerten von oben ist, dass man auf Anhieb erkennt, welcher Prädiktor ein Problem darstellt. Bei der paarweisen Korrelation kann es sowohl die eine als auch die andere unabhängige Variable sein. Zudem drückt der VIF-Wert in einer Zahl den Grad der Korrelation des einen Prädiktors mit allen anderen Prädiktoren aus. Es ist also deutlicher, welcher Prädiktor Probleme bereiten könnte.
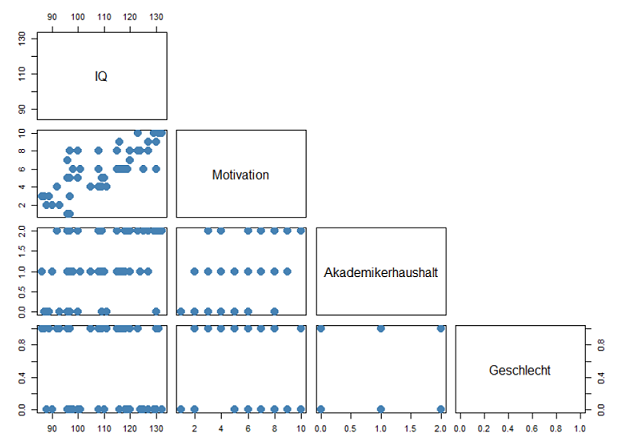
3.2 Grafische Prüfung
Die grafische Prüfung ist nur dann hilfreich, wenn die Variablen, die man betrachtet, wenigstens ordinal skaliert sind. Die in meinem Modell befindliche Variable Geschlecht ist zwar dichotom, ich nehme sie aber dennoch mit in die Streudiagrammmatrix auf. Hierzu kann man die pairs()-Funktion verwenden und gibt alle Variablen hinein. Es muss zwingend mit ~ beginnen und mit data=data_xls auf den jeweiligen Dataframe verweisen:
pairs(~IQ + Motivation + Akademikerhaushalt + Geschlecht, data=data_xls, pch = 20, cex=3, col="steelblue", upper.panel=NULL, cex.labels=1.5)
Im Ergebnis erhält man eine Streudiagrammmatrix. Wie bereits erwähnt, ist die Interpretation hier nur sinnvoll, wenn beide Variablen mindestens ordinal skaliert sind. Hier ist erkennbar, dass zwischen Motivation und IQ ein recht deutlicher linearer Zusammenhang und damit eine Korrelation vorliegt. Bedenklich ist das aber nicht unbedingt, da den Variablen jeweils ein anderes Konstrukt zugrunde liegt und gleichzeitig oben anhand der VIF-Werte keine bedenklichen Grenzen überschritten werden.
4 Gegenmaßnahmen bei Multikollinearität
Sollte es dennoch vorkommen, dass ihr Multikollinearität habt, ist eine recht einfache Vorgehensweise, diese unabhängige Variable mit dem nicht mehr akzeptablen VIF-Wert wegzulassen. Das alleinige Argument kann hier natürlich nicht nur der VIF-Wert sein. Vielmehr sollte inhaltlich geprüft werden, ob hinter den Variablen dasselbe Konstrukt liegt, also eine redundante Messung vorliegt. Wenn beispielsweise der IQ-Test und ein anderer Intelligenztest gleichzeitig aufgenommen wurden, würden sie sich sehr wahrscheinlich als redundant zeigen. Eine hohe bivariate Korrelation sowie ein hoher VIF-Wert wären die Folge.
Demgemäß würde man sich hier für das Weglassen einer der beiden Variablen entscheiden und das Modell dann erneut rechnen.
5 Weiterführende Literatur
- Field, A. P., Miles, J., Field, Z. (2012). Discovering statistics using R. London ; Thousand Oaks.
- Kutner, M. H. (2005). Applied linear statistical models. Boston: McGraw-Hill Irwin.
6 Videotutorial



