Inhaltsverzeichnis
1 Ziel des t-Test bei unabhängigen Stichproben in SPSS
Der t-Test für unabhängige Stichproben testet, ob bei zwei unabhängigen Stichproben die Mittelwerte unterschiedlich sind (Allgemeine Beschreibung).
Die Berechnung in Excel und R.Für abhängige Stichproben ist der t-Test für verbundene Stichproben zu rechnen.
Sind die folgenden Voraussetzungen nicht erfüllt, solltet ihr einen Mann-Whitney-U-Test rechnen.
2 Voraussetzungen des t-Test bei unabhängigen Stichproben in SPSS
Die wichtigsten Voraussetzungen sind:
- zwei voneinander unabhängige Stichproben/Gruppen
- metrisch skalierte y-Variable
- normalverteilte y-Variable innerhalb der Gruppen (in einem separaten Artikel zum Test auf Normalverteilung)
- Homogene (nahezu gleiche) Varianzen der y-Variablen der Gruppen, sofern Gruppen nicht in etwa gleich groß sind („Augentest“ oder notfalls Levene-Test über die Ausgabe beim Durchführen des t-Test)
- Optional: fehlende Werte definiere, fehlende Werte identifizieren und fehlende Werte ersetzen
- Achtung: Mindeststichprobengröße bedenken – über eine Poweranalyse zu ermitteln
3 Durchführung des t-Test bei unabhängigen Stichproben in SPSS
Über das Menü in SPSS: Analysieren > Mittelwerte und Proportionen vergleichen > T-Test für unabhängige Stichproben
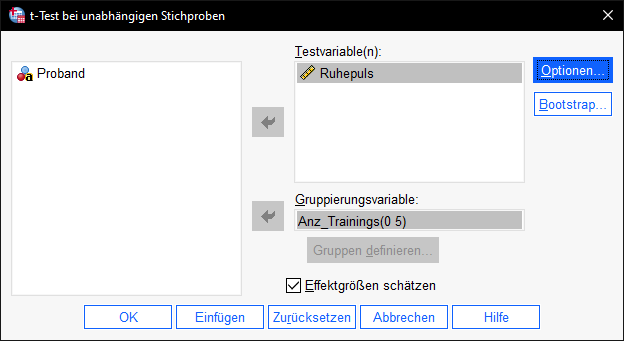
Unter Optionen 95% Konfidenzintervall und „Fallausschluss Analyse für Analyse“.
Als Gruppierungsvariable ist das die beiden Gruppen trennende Merkmal/Variable auszuwählen und die beiden Gruppen anhand der Merkmalsausprägungen (zu prüfen über die Variablenansicht und die Wertelabels) zu definieren.
4 Ergebnisse des t-Test bei unabhängigen Stichproben in SPSS
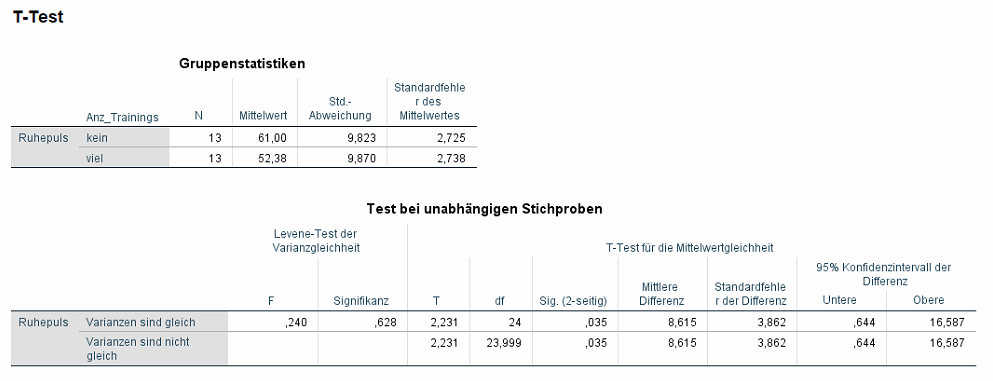
Man erhält drei Tabellen, (I) die Gruppenstatistiken, (II) die Tabelle für den t-Tets bei unabhängigen Stichproben sowie (III) die Tabelle für Effektgrößen/Effektstärken (letztere erst ab SPSS 27, siehe Abschnitt 6).
5 Interpretation des t-Test bei unabhängigen Stichproben in SPSS
1. Zunächst kann man im Beispiel an den Gruppenstatistiken erkennen, dass die Gruppe mit keinen Trainings einen Ruhepuls von durchschnittlich 61 hat. Die Gruppe mit vielen Trainings hat einen mittleren Ruhepuls von 52,38. Die Frage ist, ob diese Unterschiede überzufällig (statistisch „signifikant“) sind. Hierzu bedarf es des t-Tests.
2. Bevor allerdings auf den t-Test geschaut werden darf, muss noch die Varianzhomogenität bzw. -gleichheit geprüft werden. Die Voraussetzung der Varianzhomogenität kann mit dem Levene-Test geprüft werden, es ist aber davon abzuraten – siehe der blaue Kasten etwas weiter unten.
Daher hier nur der Vollständigkeit wegen: Die Nullhypothese lautet, dass die Varianzen homogen sind. Die Signifikanz sollte demzufolge über 0,05 liegen, damit sie nicht verworfen werden kann und den beiden Stichproben homogene Varianzen bescheinigt werden.
Die entsprechende Stelle ist mit rot markiert und im Beispiel liegt die Signifikanz beim Test auf Varianzhomogenität deutlich über 0,05 – die Nullhypothese von Varianzhomogenität kann also nicht verworfen werden.

- Sind die Gruppen in etwa gleich groß oder die Stichprobe groß (N > 100), ist Varianzhomogenität nicht notwendig. (vgl. Field (2018), S. 259)
- Der Levene’s Test ist bei großen Stichproben zu sensitiv und bei kleinen Stichproben zu liberal. Anders ausgedrückt: bei großen Stichproben führen vernachlässigbare Abweichungen zur Verwerfung der Nullhypothese und bei kleinen Stichproben hat der Test zu wenig Power, Abweichungen erkennen zu können (ebda.). Der Levene’s Test ist faktisch unzuverlässig und damit nutzlos für seriöse Analysen. Von seiner Verwendung sollte daher abgesehen werden!
- Eine pauschale Korrektur mittels des Welch-Tests wird empfohlen (ebda.). Liegt keine Verletzung vor, zeigt der Welch-Test dieselben Ergebnisse wie der „normale t-Test“, ansonsten werden die Freiheitsgrade (df) angepasst und variierende p-Werte sind die Folge.
3. Im Falle von Varianzhomogenität spielt nur die Zeile „Varianzen sind gleich“ eine Rolle. Wie bereits erwähnt, kann auch pauschal auf die Zeile „Varianzen sind nicht gleich“ geschaut werden. Die Ergebnisse sind identisch, weil in meinem Datenbeispiel kaum eine Verletzung von Varianzhomogenität besteht. Zudem sind die Gruppengrößen identisch und Varianzhomogenität ist dann ohnehin irrelevant.

ACHTUNG: Hat man bereits eine Vermutung, dass z.B. eine Gruppe einen höheren/niedrigeren Wert hat, ist dies eine gerichtete Hypothese und man muss 1-seitig testen. Sofern in den älteren SPSS-Versionen nur die zweiseitige Signifikanz angegeben ist, halbiert man den bei Sig. (2-seitig) erhaltenen Wert.
Da uns im Vorfeld (bei der Aufstellung der Hypothese) schon bewusst war, dass trainiertere Menschen in der Regel einen niedrigeren Ruhepuls haben (siehe deskriptive Statistiken), haben wir eine Wirkungsvermutung bzw. eine gerichtete Hypothese. Wir testen also einseitig und dürfen die Signifikanz sogar halbieren. Sie beträgt dann 0,0175 (SPSS rundet auf 3 Nachkomastellen 0,018) und ist natürlich immer noch hinreichend klein. ACHTUNG: Ich muss im Vorfeld die Hypothese so formuliert haben, das sie einen einseitigen Test zulässt. Ein nachträgliches Umformulieren ist nicht statthaft – kann aber freilich auch nicht vom Gutachter geprüft werden. 😉
Exkurs/Zusatzinfos:Der p-Wert/die Signifikanz des Testergebnisses wurde „früher“ immer an einer Alphagrenze gespiegelt. War p < Alpha galt der t-Test als signifikant und das Ergebnis als "belegt" (wenn überhaupt, bitte "Hypothese konnte bekräftigt werden" verwenden).
Dieses Vorgehen hat häufig dazu geführt, dass solange am Verfahren oder den Skalen herumgeschraubt wurde, bis die p-Werte unter der Alphagrenze lagen. Das ist sog. p-Hacking und mit den Regeln einer guten wissenschaftlichen Praxis nicht vereinbar!
Hinzu kommt, dass der Unterschied zwischen p = 0,051 und p = 0,049 marginal ist – die getroffenen Aussagen hinsichtlich der Nullhypothese aber fundamental unterschiedlich sind. Die Alphagrenze gilt daher in den allermeisten (aufgeklärten) Wissenschaftsbereichen als überholt. Vielmehr sind Kontext und vorherige Studienergebnisse zu beachten. Auch größere p-Werte können Hinweise auf Unterschiede/Veränderungen/Zusammenhänge sein (vgl. hierzu ausführlich Wasserstein (2016) sowie Wasserstein et al. (2019)).
Schließlich kann festgehalten werden, dass der p-Wert nur eine Funktion der Stichprobengröße ist, wenn Effekte verschieden von Null existieren.
6 Die Effektstärke – wie stark ist der Unterschied?
6.1 Cohen’s d ab SPSS 27
Die Effektstärke wird von SPSS erst ab Version 27 ausgegeben. Wie stark sich die beiden Gruppen unterscheiden, wird dabei mit Cohen’s d (bei N>20) oder Hedges‘ Korrektur (bei N<20 sowie ungleichen Varianzen) quantifiziert. Dies wird mit SPSS 27 und später standardmäßig berechnet. Ausführlich zu den Unterschieden zwischen d und korrigiertem g: Grissom, Kim (2012), S. 68f.

Diese Größe wird nun eingeordnet, idealerweise mit vergleichbaren Studien. Sollten keine existieren, werden fachspezifische Grenzen verwendet. Fehlen auch diese, kann mit Cohen (1988), S. 25-26 bzw. Cohen (1992), S. 157 eine Einordnung erfolgen:
- ab 0,2 klein,
- ab 0,5 mittel und
- ab 0,8 stark.
6.2 Cohen’s d manuell berechnen
Die Formel findet sich auf S. 20 von Cohen (1988) Statistical Power Analysis: ![\[ d = \frac{\bar{x_{1}}-\bar{x_{2}}}{s}} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-bd8c652f03d08f4a8b43268d6cbcee78_l3.png "Rendered by QuickLaTeX.com")
![\[s = \sqrt{\frac{(n_{1}-1)\cdot s_{1}^{2} + (n_{2}-1)\cdot s_{2}^{2}} {n_{1}+n_{2}-2}} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-b32a280e1481aed8257d90183dadcda9_l3.png "Rendered by QuickLaTeX.com")
![\[s = \sqrt{\frac{s_{1}^{2}- s_{2}^{2}}{2}} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-5d24176f356eb1ffe8265c3a2d384403_l3.png "Rendered by QuickLaTeX.com")
Im Beispiel sind die Mittelwerte 61 und 52,38 (siehe oben) sowie die gepoolte Standardabweichung 9,85. Eingesetzt in die obige Formel:
![\[ d = \frac{61-52,38}{9,85}} = 0,875 \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-37bf6685a969ee240a43669fe9ff5595_l3.png "Rendered by QuickLaTeX.com")
6.3 Effektstärkemaß r manuell berechnen
Eine dritte Möglichkeit ist die manuelle Berechnung von r sowie die Beurteilung anhand Cohen: Statistical Power Analysis for the Behavioral Sciences (1988), S. 79-81. Cohen selbst merkt aber an, dass die Effektstärkemaße und deren Klassengrenzen nicht 1:1 vergleichbar sind. Vorzuziehen ist Cohen’s d. Die Berechnung von r erfolgt über die Formel mit t² als quadrierter T-Wert und df als degrees of freedom (Freiheitsgrade). ![\[ r = \sqrt{\frac{t^2}{t^2+df}} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-0a866ea8e34c99c0fa81c3fda24ee683_l3.png "Rendered by QuickLaTeX.com")
Ab 0,1 ist es ein schwacher Effekt, ab 0,3 ein mittlerer und ab 0,5 ein starker Effekt.
Im Beispiel ist der t-Wert 2,231 und die Freiheitsgrade (df) 24. Eingesetzt in die Formel:
![\[ r = \sqrt{\frac{2,231^2}{2,231^2+24}}= 0,414 \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-35b45695fe7a688138a8301fe2e1e5c5_l3.png "Rendered by QuickLaTeX.com")
Das Ergebnis von 0,414 liegt über der Grenze zur mittleren Effektstärke und der Unterschied ist damit lauut Cohen ein mittelstarker Unterschied. Allerdings gibt es neuere Richtlinien bzgl. r, die von Gignac, Szodorai (2016) vorgeschlagen wurden, die bei 0,1 (klein), 0,2 (mittel) und 0,3 (groß) liegen. Demnach wäre der Unterschied im Beispiel ein großer.
Auch hierzu gibt es ein kleines Video auf meinem YouTube-Kanal:


7 Reporting des t-Tests bei unabhängigen Stichproben
Gruppenmittelwerte und Standardabweichungen sind zu berichten. Zusätzlich die t-Statistik mit Freiheitsgraden, der p-Wert und die Effektstärke (Cohens d bzw. Hedges‘ Korrektur): t(df)=t-Wert; p-Wert; Effektstärke.Untrainierte Probanden (M = 61; SD = 9,82) haben gegenüber trainierten Probanden (M = 52,38; SD = 9,87) einen signifikant höheren Ruhepuls, t(24) = 2,23; p = 0,035; d = 0,88. Nach Cohen (1992) ist dieser Unterschied groß.
8 Literatur
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences. New York, NY: Psychology Press, Taylor & Francis Group
- Cohen, J. (1992). A power primer. Psychological bulletin, 112(1), 155-159.
- Field, A. (2018), Discovering Statistics Using IBM SPSS, SAGE.
- Gignac, G. E., & Szodorai, E. T. (2016). Effect size guidelines for individual differences researchers. Personality and individual differences, 102, 74-78.
- Grissom, R. J., & Kim, J. J. (2012). Effect sizes for research: Univariate and multivariate applications. New York: Routledge.
- Wasserstein, R. L., & Lazar, N. A. (2016). The ASA statement on p-values: context, process, and purpose. The American Statistician, 70(2), 129-133.
- Wasserstein, R. L., Schirm, A. L., & Lazar, N. A. (2019). Moving to a world beyond “p< 0.05”. The American Statistician, 73(sup1), 1-19.


