Der Shapiro-Wilk-Test in R hilft bei der Beurteilung, ob eine Variable, wahlweise auch Residuen im Rahmen einer linearen Regression, normalverteilt sind. Allerdings sollte man bei der Beurteilung vorsichtig sein, was auch für den Kolmogorov-Smirnov-Test auf Normalverteilung gilt.
Inhaltsverzeichnis
1 Nullhypothese des Shapiro-Wilk-Tests
Der Shapiro-Wilk-Test prüft die zu testende Variable auf Normalverteilung.
2 Rechnen des Shapiro-Wilk-Tests in R
Der Shapiro-Wilk-Test wird in R über die shapiro.test()-Funktion berechnet.
Es wird nur die zu testende Variable benötigt, die auf Abweichung von einer Normalverteilung geprüft werden soll.
Für meine zu testende Variable “Gewicht” aus dem Data Frame “df” sieht der Shapiro-Wilk-Test wie folgt aus:
shapiro.test(df$Gewicht)
Im Ergebnis erhält man eine Teststatistik W sowie den p-Wert:
Shapiro-Wilk normality test
data: df$Gewicht
W = 0.85935, p-value = 2.38e-05
3 Beurteilen des Shapiro-Wilk-Tests in R
Der p-Wert wird zur Prüfung der Nullhypothese verwendet. Liegt der p-Wert unter dem im Vorfeld bestimmten Alphaniveau (zumeist 5% = 0,05), wird die Nullhypothese verworfen. Wir erinnern uns, dass die Nullhypothese beim Shapiro-Wilk-Test gleichbedeutend mit Normalverteilung ist.
Folglich führt ein Verwerfen der Nullhypothese dazu, dass man keine Normalverteilung attestieren kann.
Dies trifft auf das oben gerechnete Beispiel zu. Der p-Wert ist mit p = 2,38e-05 sehr klein. Das Komma wandert um 5 Stellen nach links. 2,38e-05 = 0,0000238 und somit deutlich < 0,05.
Somit muss die Nullhypothese von Normalverteilung verworfen werden.
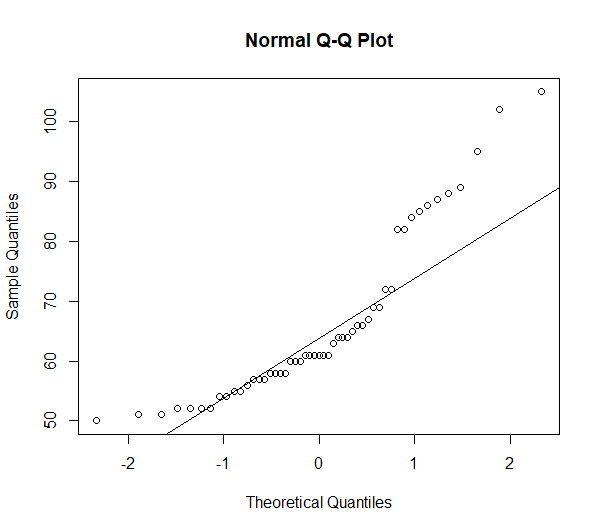
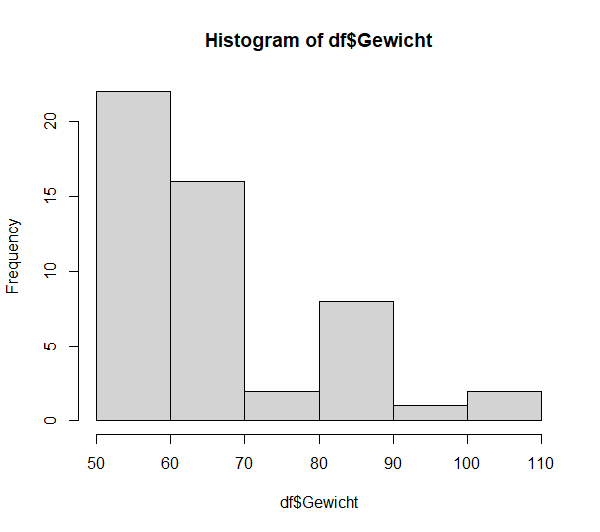
Beim Betrachten des Q-Q-Plots (näheres zur Lesart) und Histogramms wird schnell klar, dass dies korrekt scheint. Die Abweichungen von einer Normalverteilung sind zu groß.
hist(df$Gewicht)
qqnorm(df$Gewicht)
qqline(df$Gewicht)
4 Zweites Beispiel
shapiro.test(df2$x)
Im Ergebnis erhält man:
Shapiro-Wilk normality test
data: df2$x
W = 0.99958, p-value = 0.3661
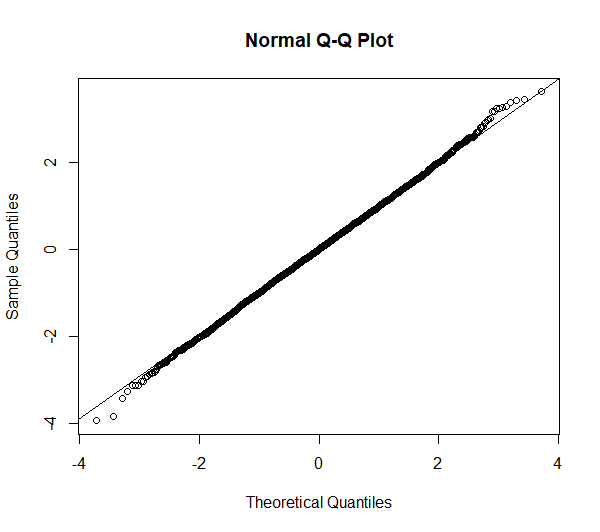
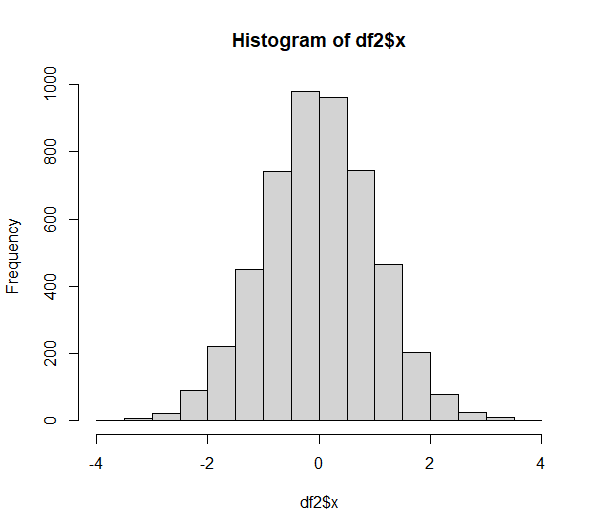
Die Nullhypothese wird bei dieser (im Vorfeld absichtlich als normalverteilte Variable erstellte) Verteilung mit 5000 Beobachtungen mit einem p-Wert von p = 0,366 nicht verworfen. Die Testvariable ist normalverteilt, was sich beim Blick auf Q-Q-Plot und Histogramm bekräftigt:
5 Vorsicht beim Shapiro-Wilk-Test!
Ein letztes Beispiel dient dazu, vor der alleinigen Verwendung des Ergebnisses des Shapiro-Wilk-Tests zu warnen.
Eine Variable, analog zu oben, mit 5000 Beobachtungen, allerdings mit ein paar Beobachtungen an den Verteilungsrändern um 3 bzw. -3 und 4 bzw. -4.
Shapiro-Wilk normality test
data: df2$x
W = 0.99297, p-value = 5.227e-15
Das Ergebnis ist hier deutlich: eine Verwerfung der Nullhypothese von Normalverteilung. Allerdings stellt sich die Frage, ob das gerechtfertigt ist, wenn Q-Q-Plot und Histogramm betrachtet werden:
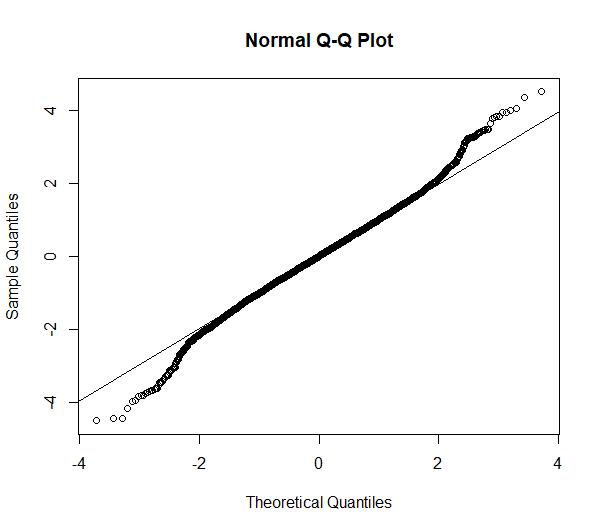
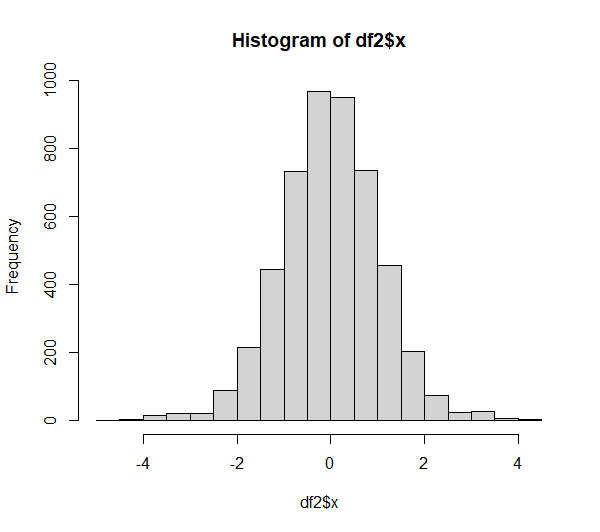
Hier kann geschlossen werden, dass, obwohl der Shapiro-Wilk-Test hier keine Normalverteilung attestiert (bei jeglichen Alphaniveaus), grafisch betrachtet aber kaum Grund zum Zweifeln an Normalverteilung besteht.
Die im Q-Q-Plot sichtbaren Abweichungen an den Enden der Verteilung sind unter praktischen Gesichtspunkten im wahrsten Sinne des Wortes normal. In solchen Fällen ist die typische Anforderung parametrischer Tests an z.B. normalverteilte Residuen erfüllt, da eine “in etwa Normalverteilung” ausreicht – obwohl der Shapiro-Wilk-Test keine Normalverteilung attestiert.
- Der Grund für dieses Testergebnis ist die höhere Stichprobengröße.
- Diese führt zu einer höheren Power (= Teststärke) des Shapiro-Wilk-Tests.
- Eine höhere Power bedeutet, dass kleinere Abweichungen wahrscheinlicher entdeckt werden.
- Kleine Abweichungen führen bei großen Stichproben also letztlich zur Verwerfung der Nullhypothese (von Normalverteilung)
Im Artikel “The large sample size fallacy” von Lantz (2013) wird dies ausführlich beschrieben.
Zusammengefasst aus dem Abstract: “The results of studies based on large samples are often characterized by extreme statistical significance despite small or even trivial effect sizes. Interpreting such results as significant in practice without further analysis is referred to as the large sample size fallacy in this article.“
5 Videotutorial

6 Literatur
Lantz, B. (2013). The large sample size fallacy. Scandinavian journal of caring sciences, 27(2), 487-492.


