Inhaltsverzeichnis
1 Ziel der Moderation in SPSS (Interaktion)
Eine Moderation (auch Interaktion) unterstellt den Einfluss einer zusätzlichen Variable (=Moderator) auf eine Beziehung zwischen einer unabhängigen Variable (X) und einer abhängigen Variable (Y). Man kann auch von der Verstärkung oder Abschwächung eines vorhandenen Effektes sprechen. Dieser Artikel zeigt, wie man dies in SPSS mit PROCESS modelliert und berechnet.
2 Voraussetzungen der Moderation (Interaktion)
Die wichtigsten Voraussetzungen sind:
- linearer Zusammenhang zwischen x-Variablen und y-Variable
- metrisch skalierte y-Variable (mitunter ist auch ordinal vertretbar – da gibt es große Diskussionen zu :-D)
- keine Multikollinearität – Korrelation der x-Variablen sollte nicht zu hoch sein
- normalverteilte Fehlerterme – Achtung beim analytischen Testen mit Kolmogorov-Smirnov und Shapiro-Wilk-Test
- Homoskedastizität – homogen streuende Varianzen des Fehlerterms (grafische Prüfung oder analytische Prüfung)
- Optional: fehlende Werte definieren, fehlende Werte identifizieren und fehlende Werte ersetzen
3 Das Prinzip der Moderation
Eine Moderation, auch Interaktion genannt, unterstellt einen moderierenden Einfluss einer Variable (M) auf einen Zusammenhang zwischen zwei Variablen (X->Y). Im Beispiel werden sind Mathematik-Fähigkeiten die x-Variable und die Fähigkeit wissenschaftlich zu arbeiten die y-Variable. Deren Zusammenhang wird durch die Lesefähigkeiten (M) moderiert.
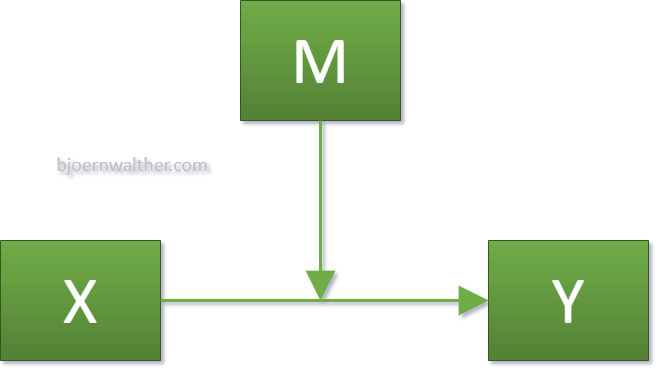
Da SPSS keine Möglichkeit bietet, eine Moderation direkt zu modellieren, muss eine Umwandlung bzw. Transformation vorgenommen werden. Der Moderator (M), die unabhängige Variable (X) als auch der Interaktionseffekt (X*M) werden gleichzeitig als unabhängige Variablen aufgenommen. Dies zeigt die folgende Abbildung:
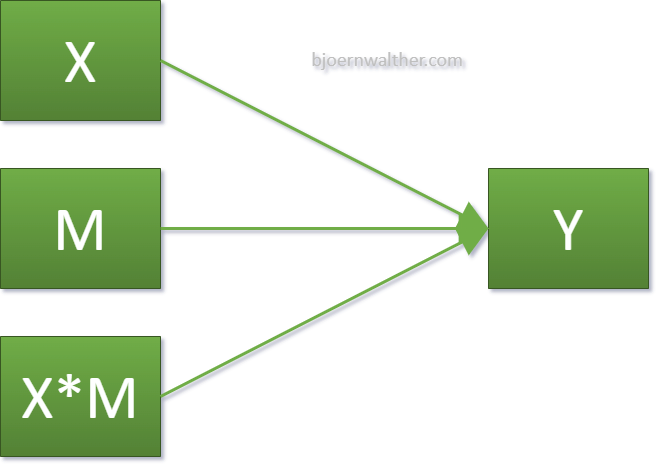
Zum Glück wird einem dies dank des PROCESS-Plugins abgenommen.
4 Durchführung der Moderation in SPSS mit PROCESS
4.1 Definition des Modells

Zuerst wird das PROCESS-Plugin in der jeweiligen Version geöffnet – hier 4.2.

Die entsprechenden Variablen sind nun zuzuordnen. Im Beispiel ist Fähigkeit wissenschaftlich zu arbeiten („science“) die y-Variable, Mathematikfähigkeiten („math“) die x-Variable und die Lesefähigkeiten („read“) der Moderator.
In PROCESS wird der Moderator zur Unterscheidung zum Mediator immer mit W bezeichnet.
Unter Model number wird 1 beibehalten.
4.2 Weitere Optionen

Unter dem Button „Options“ verbergen sich weitere hilfreiche Möglichkeiten, die Interaktion einfacher rechnen zu lassen.
Empfehlenswert sind:
- Generate code for visualizing interactions
- Heteroscedasticity-consistent inference HC3 (Davidson-MacKinnon) – entsprechend Hayes (2007), S. 716 – im Falle vorliegender Heteroskedastizität werden die Standardfehler der Koeffizienten robust geschätzt. Liegt Homoskedastizität vor, ändert sich nichts.
- Conditioning values kann 16th, 50th, 84th percentiles angehakt bleiben. Empfehlenswert ist es aber besonders wenn der Moderator eine schiefe Verteilung hat. Sind die Verteilungen nicht schief bzw. gibt es keine den Mittelwert verzerrende „Ausreißer“ beim Moderator, kann auch -1SD, Mean, +1SD gewählt werden.
- Johnson-Neyman output
4.3 Lange Variablennamen
Unter dem Button „Long variable names“ ist noch die Möglichkeit gegeben, PROCESS mitzuteilen, dass die Variablennamen länger als 8 Zeichen sind.
Aber ACHTUNG: Wenn die ersten 8 Zeichen zweier oder mehrere Variablennamen gleich sind, kommt es hier zu fehlerhaften Berechnungen!
4.4 Kategoriale Variablen
Unter „Multicategorical“ kann festgelegt werden, ob es die x-Variable oder der Moderator eine kategoriale Variable mit 3 oder mehr Ausprägungen ist. Ist dies der Fall und wird hier entsprechend definiert, werden von PROCESS automatisch Dummys angelegt und in der Berechnung berücksichtigt. Im Rahmen dieses Beispiels ist dies nicht gegeben und wird daher ignoriert. Für Kovariate müssen jedoch im Vorfeld Dummys kodiert sein.
5 Ergebnistabellen von PROCESS
Nach der Berechnung durch PROCESS bekommt man einen Output, der optisch etwas vom normalen SPSS-Output abweicht. Die Interpretation erfolgt schrittweise in Punkt 6 dieses Artikels.


6 Interpretation der Ergebnistabellen von PROCESS in SPSS
6.1 Allgemeine Modellinterpretation
Der Übersicht wegen habe ich die Interpretation in die Teile A-E aufgeteilt.

A – Informationen zum Modell

Hier ist lediglich erkennbar, welche Modellnummer (hier: 1 – einfache Moderation) gerechnet wurde und welche Variablen eingehen. Schließlich wird bei Sample Size die Stichprobengröße (hier: N = 200) angegeben.
B – F-Test und Modellgüte

Der Output beginnt mit dem multiplen Korrelationskoeffizient (R) und dessen Quadrat (R-sq = R² = Bestimmtheitsmaß).
- Das Bestimmtheitsmaß R² gibt an, wie viel Prozent der Varianz der abhängigen Variable (Y) durch das Modell erklärt werden. Hier sind es 0.4904, also 49,04% der Varianz der abhängigen Variable („science“), die durch das vorliegende Modell erklärt werden.
- Der F-Test zeigt, ob das Modell einen Erklärungsbeitrag leistet. F(3, 196) = 74.45, p < .001.
- Die Nullhypothese des F-Tests (Modell liefert keinen Erklärungsbeitrag) wird aufgrund des sehr geringen p-Wertes verworfen.
- Das Modell und dessen Ergebnisse können weiter interpretiert werden.
C – Modellkoeffizienten

Hier sind alle Koeffizienten der in das Modell eingehenden Variablen sowie die Konstante aufgelistet.
Ein erster Blick geht in die Spalte p, wahlweise LLCI und ULCI.
- Die p-Werte zeigen an, ob die Nullhypothese keines Zusammenhanges der jeweiligen Variable verworfen werden kann. Sind die p-Werte unter der Alphagrenze (i.d.R 0.05), kann ein Zusammenhang beobachtet werden.
- Ein Zusammenhang kann ebenso mit dem LLCI (Lower Limit Confidence Interval) sowie ULCI (Upper Limit Confidence Interval) geprüft werden.
- Sofern beide Grenzen des Konfidenzintervalls positiv oder negativ sind (die 0 ist NICHT im Intervall), kann ein Nulleffekt zu 95% Konfidenz ausgeschlossen werden – ein Zusammenhang kann beobachtet werden.
- Im Modell sind die p-Werte aller Variablen gering genug und es kann zunächst von Zusammenhängen gesprochen werden – die Art des Interaktionseffektes bestimmt allerdings, welche Effekte interpretiert werden drüfen (weiter, s.u.).
Ein zweiter Blick geht in die Spalte coeff.
- Ein positiver Koeffizient zeigt einen positiven Zusammenhang zwischen unabhängiger und abhängiger Variable an, ein negativer Koeffizient zeigt entsprechend einen negativen Zusammenhang.
- Sollte der Interaktionseffekt einen hinreichend kleinen p-Wert haben (hier p = 0.0279) ist dieser primär zu interpretieren.
- Ich empfehle wärmstens eine grafische Betrachtung des Interaktionseffektes, um Klarheit über dessen Art zu erhalten.
Die Interpretation von „Haupteffekten“ mit hinreichend kleinen p-Werten erfolgt – in Abhängigkeit der Art des vorliegenden Interaktionseffektes – auf drei Arten und Weisen.
Angenommen, der Interaktionseffekt wäre nicht beobachtbar, würde man einen positiven Einfluss von „math“ auf „science“ sowie „read“ auf „science“ erkennen können (grafisch, siehe Abschnitt E). Würde man den Koeffizienten interpretieren wollen, ist die o.g. Mittelwertzentrierung im Vorfeld durchzuführen. Die Koeffizienten wäre dann (0,4258 für „math“ und 0,3666 für „read“ – hier nicht gezeigt) und drücken die Steigerung in „science“ aus, wenn die jeweilige Variable um 1 zunimmt und alle anderen Variablen 0 sind..
Der Koeffizient des Interaktionsterms (Int_1) ist negativ, was für eine Dämpfung spricht. Allerdings sind weitere noch folgende Betrachtungen hierfür hilfreich.
D – Beitrag des Interaktionseffektes zum Modell
![]()
Die beobachtbare Interaktion von „math“ und „read“ im Modell sorgt für eine Steigerung von R² in Höhe von .0121 = 1,21% mit F(1,196) = 4.91, p = 0.0279. Das Modell mit Interaktion ist also statistisch betrachtet besser als das Modell ohne Interaktion und erklärt im Vergleich 1,21% mehr der Varianz der abhängigen Variable („science“).
Ob diese Steigerung groß ist, hängt von vergleichbaren Studien bzw. dem Forschungsfeld ab.
E – Bedingte Effekte des Hauptprädiktors bei Werten des Moderators

- In der ersten Spalte stehen die im Vorfeld definierten Conditioning values. Im Beispiel habe ich die Perzentile 16, 50 und 84 gewählt, die für „read“ den Werten 42, 50 und 63 entsprechen. Die andere Option (Mittelwert, Mittelwert-Standardabweichung, Mittelwert+Standardabweichung) würde ebenso 3 Werte zur Folge haben.
- In der zweiten Spalte (Effect) steht die Auswirkung auf die abhängige Variable („science“) bei Konstanthaltung der x-Variable („math“) bei gleichzeitiger Änderung des Moderators („read“).
- Die p-Werte sind entsprechend zu beachten – hier sind alle klein genug, die konditionalen Effekte zu interpretieren.
- Hier ist erkennbar, dass bei einer Zunahme des Moderators („read“) der positive Effekt von „math“ auf die abhängige Variable („science“) schwächer wird.
- Anders ausgedrückt: der positive Effekt von „math“ auf „science“ wird schwächer, je höher „read“ ist.
6.2 Grafische Betrachtung des Interaktionseffektes
Da die in E in Abschnitt 6.1 durchgeführte Interpretation erst mit etwas Übung gut klappt, empfiehlt sich eine grafische Betrachtung. Diese wird glücklicherweise, sofern in den Optionen angefordert, von PROCESS mitgeliefert – zumindest über Umwege.
Zunächst ist im Output an die Stelle zu scrollen, wo „DATA LIST FREE/“ zu finden ist.
Per Doppelklick wird der Output editier- sowie kopierbar. Der Teil ab DATA LIST FREE bis zum Ende (inklusive .) ist zu kopieren.

Anschließend wird ein neues Syntaxfenster über Datei > Neu > Syntax geöffnet:

Nun wird der kopierte Syntax lediglich eingefügt, komplett markiert und mit Klick auf den grünen Pfeil ausgeführt.

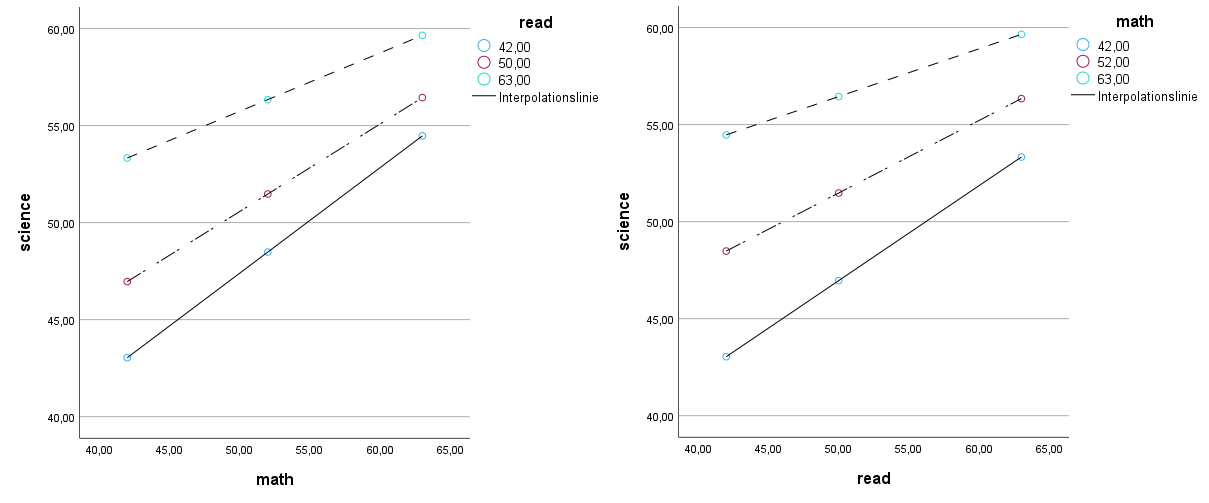
Die resultierende Grafik ist ein Diagramm mit 9 Punkten.
Jeweils 3 farblich identische Punkte gehören zusammen und stellen das jeweilige Niveau des Moderators („read“) dar.
Im Beispiel ist die untere „Linie“ für die niedrige Ausprägung 42 des Moderators, die rote „Linie“ für die mittlere Ausprägung 50 des Moderators und die türkisfarbene „Linie“ für die hohe Ausprägung 63 des Moderators.

Über den Diagrammeditor (Doppelklick ins Diagramm) kann eine Interpolationslinie für die jeweilige Ausprägung des Moderators und deren Punkte hinzugefügt werden, um es optisch etwas zu vereinfachen.

Eine kleine optische Anpassung der Farben führt zu folgender Abbildung:

- Hiermit ist nun auch etwas besser erkennbar, wie sich der Zusammenhang zwischen x-Variable („math“) und y-Variable („science“) zu den verschiedenen Niveaus des Moderators („read“) verhält.
- Prinzipiell besteht zwischen x-Variable („math“) und y-Variable („science“) ein positiver Zusammenhang.
- Je höher der Moderator („read“) ist, desto höher ist jeweils das Niveau der y-Variable („science“).
- Die Steigung der Geraden (Zusammenhang x-Variable und y-Variable) ist jedoch auf hohem Niveau des Moderators („read“) flacher.
- Das deutet daraufhin, dass ein hoher „math“-Score zwar zu einem höheren „science“-Score führt, allerdings ist der Zugewinn schwächer, wenn der „read“-Score höher ist.
- Eine Dämpfung des positiven Zusammenhanges durch ein höheres Niveau des Moderators ist erkennbar.
- Schließlich kann gesagt werden, das folgender Schluss nahe liegt: Mathematik-Fähigkeiten führen zu höheren Wissenschaftsfähigkeiten, allerdings ist der Zugewinn geringer, wenn bereits höhere Lesefähigkeiten vorliegen. Insgesamt ist ein hohes Niveau an Mathematik- und Lesefähigkeiten für das höchste Niveau an Wissenschaftsfähigkeiten verantwortlich.
6.3 Arten von Interaktionseffekten
Es gibt 3 Arten von Interaktionseffekten, die hier stilisiert dargestellt sind. Mit der Erkenntnis, um welche Art des Interaktionseffektes sich handelt, ist verbunden, ob und wenn ja, welche Haupteffekte interpretiert werden dürfen.
Die abhängige Variable wird in den nachfolgenden Diagrammen immer auf der y-Achse abgetragen.
Zunächst wird die unabhängige Variable in niedriger und hoher Ausprägung (UVn, UVh) auf der x-Achse entsprechend für eine niedrige und eine hohe Moderatorvariable (Mn, Mh) abgetragen (obiges Diagramm).
Danach werden die Variablen umgedreht: die Moderatorvariable wird nun in niedriger und hoher Ausprägung ((Mn, Mh) auf die x-Achse gelegt und in Abhängigkeit der niedrigen und hohen unabhängigen Variable (UVn, UVh) abgetragen.
6.3.1 Ordinale Interaktion
Nur im Falle eines ordinalen Interaktionseffektes sind die Haupteffekte (von unabhängiger Variable und Moderator) auch global interpretierbar.
Die Geraden sollten beide das gleiche Vorzeichen haben, im Sinne einer jeweils positiven oder negativen Steigung. Die Geraden dürfen sich auch schneiden, aber nur wenn sie beide weiterhin in die gleiche Richtung zeigen.
- In Diagramm 1 wirkt je Faktorstufe (Mh sowie Mn) eine Zunahme der UV positiv auf die AV.
- In Diagramm 2 wirkt ebenfalls je Faktorstufe (UVh sowie UVn einen Zunahme von M positiv auf die AV.


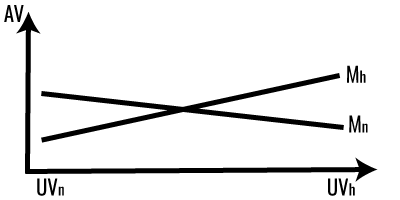
6.3.2 Hybride Interaktion
Im Falle eines hybriden Interaktionseffektes ist nur ein Haupteffekt (entweder von unabhängiger Variable oder Moderator) auch global interpretierbar.
- In Diagramm 1 wirkt je Faktorstufe (Mh sowie Mn) eine Zunahme der UV unterschiedlich auf die AV.
- In Diagramm 2 wirkt ebenfalls je Faktorstufe (UVh sowie UVn einen Zunahme von M positiv auf die AV.
6.3.3 Disordinale Interaktion
Nur im Falle eines disordinalen Interaktionseffektes sind die Haupteffekte (von unabhängiger Variable und Moderator) NICHT global interpretierbar.
Die Geraden haben hierbei beide gegenseätzliche Vorzeichen, im Sinne einer jeweils positiven und negativen Steigung je Diagramm. Die Geraden können, müssen sich aber nicht schneiden
- In Diagramm 1 wirkt je Faktorstufe (Mh sowie Mn) eine Zunahme der UV positiv auf die AV.
- In Diagramm 2 wirkt ebenfalls je Faktorstufe (UVh sowie UVn einen Zunahme von M positiv auf die AV.

6.3.4 Prüfung in SPSS
Über den PROCESS-Output erhält man stets eine Variante für die Syntax, wo die x-Variable auf der x-Achse abgetragen ist und der Moderator mittels drei Linien dargestellt wird. Diese kann leicht in die zweite Variante umgewandelt werden, indem der Syntax minimal angepasst wird. Am Beispiel sollte es deutlich werden, dass in der letzten Zeile lediglich die erste und letzte Variable getauscht werden müssen:
DATA LIST FREE/
math read science.
BEGIN DATA.
42,0000 42,0000 43,0389
52,0000 42,0000 48,4818
63,0000 42,0000 54,4690
42,0000 50,0000 46,9586
52,0000 50,0000 51,4746
63,0000 50,0000 56,4421
42,0000 63,0000 53,3282
52,0000 63,0000 56,3378
63,0000 63,0000 59,6485
END DATA.
GRAPH/SCATTERPLOT=
math WITH science BY read.
Durch Tausch von math und read (Änderung fett hervorgehoben) wird obige Syntax zu:
DATA LIST FREE/
math read science.
BEGIN DATA.
42,0000 42,0000 43,0389
52,0000 42,0000 48,4818
63,0000 42,0000 54,4690
42,0000 50,0000 46,9586
52,0000 50,0000 51,4746
63,0000 50,0000 56,4421
42,0000 63,0000 53,3282
52,0000 63,0000 56,3378
63,0000 63,0000 59,6485
END DATA.
GRAPH/SCATTERPLOT=
read WITH science BY math.
Das Eregbnis im Beispiel entspricht der ordinalen Interaktion (siehe 6.3.1). Beide Schaubilder zeigen eindeutige Verläufe. Zum einen nimmt „math“ auf allen Faktorstufen von „read“ zu (linkes Diagramm), zum anderen nimmt „read“ auf allen Faktorstufen von „math“ zu. Damit sind auch die Haupteffekte global interpretierbar. Da sowohl math (p = .0007) als auch read (p = .001) hinreichend kleine Signifikanzen sind, können die Koeffizienten – neben der Interaktion – auch global interpretiert werden. Beide sind positiv, somit nimmt „science“ bei der jeweiligen Steigerung von math als auch read zu.
6.4 Johnson-Neyman Output
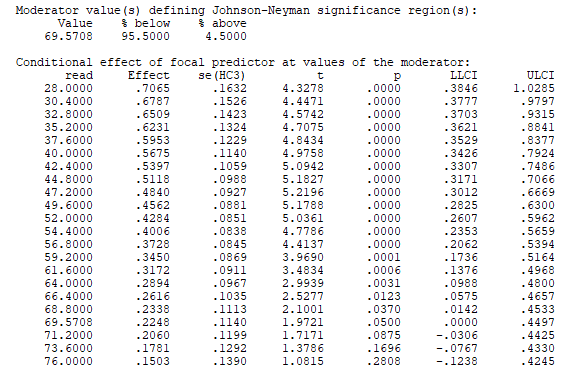
Der Johnson-Neyman Output von PROCESS ist nur eine detaillierte Variante des schon bei E in Abschnitt 6.1 beschriebenen Zusammenhanges.
Man sieht hierbei jeweils auf welchem Niveau des Moderators („read“) welcher Effekt hinsichtlich der y-Variable („science“) beobachtbar ist und welche Signifikanz dieser Effekt hat.
Erkennbar ist, dass vom niedrigen Niveau des Moderators „read“ (28) bis zum hohen Niveau des Moderators „read“ (69.5708) die p-Werte klein genug sind und analog die Konfidenzintervalle die 0 nicht beinhalten (Rundung beim KI für 69.5708 beachten).
Zusätzlich kann beobachtet werden, dass der Effekt eines steigenden Moderators („read“) zwar zu einer Zunahme der y-Variable („science“) führt, diese Zunahme aber immer kleiner ausfällt. Diese Beobachtung deckt sich entsprechend mit den schon erzielten Erkenntnissen, ist aber noch ein gutes Stück differenzierter und somit aufschlussreicher.
7 Videotutorial

8 Datensatz
Der von mir im Beispiel verwendete Datensatz ist der hsb2-Datensatz, der unter openintro.org im csv-Format heruntergeladen und in SPSS importiert werden kann.
9 Literatur
- Hayes, A. F., & Cai, L. (2007): Using heteroskedasticity-consistent standard error estimators in OLS regression: An introduction and software implementation. Behavior research methods, 39(4), 709-722
- Hayes, A. F. (2018): Introduction to Mediation Moderation and Conditional Process Analysis Second Edition : A Regression-Based Approach. New York; London: The Guilford Press.


