Inhaltsverzeichnis
1 Ziel des Friedman-Test in R
Der Friedman-Test ist ein nicht parametrischer Mittelwertvergleich bei 3 oder mehr abhängigen Stichproben. Die Nullhypothese geht von Gleichheit der Gruppen- bzw. Zeitpunktmittelwerte aus. Der Friedman-Test verwendet Ränge statt die tatsächlichen Werte und ist das Gegenstück zur ANOVA mit Messwiederholung, allerdings hat er nicht solche strengen Voraussetzungen.
2 Voraussetzungen des Friedman-Tests in R
- mindestens drei voneinander abhängige Stichproben/Gruppen
- ordinal oder metrisch skalierte y-Variable
- normalverteilte y-Variable innerhalb der Gruppen nicht nötig
- Daten müssen für dieses Tutorial im Long-Format vorliegen -> Umwandlung wide-format zu long-format
3 Grafische Veranschaulichung mittels Boxplot und deskriptive Statistiken
3.1 Boxplot
Dieser Schritt ist optional und dient lediglich der Einordnung und dem Gewinn eines ungefähren Gefühls, was zwischen den Zeitpunkten für Unterschiede bestehen.
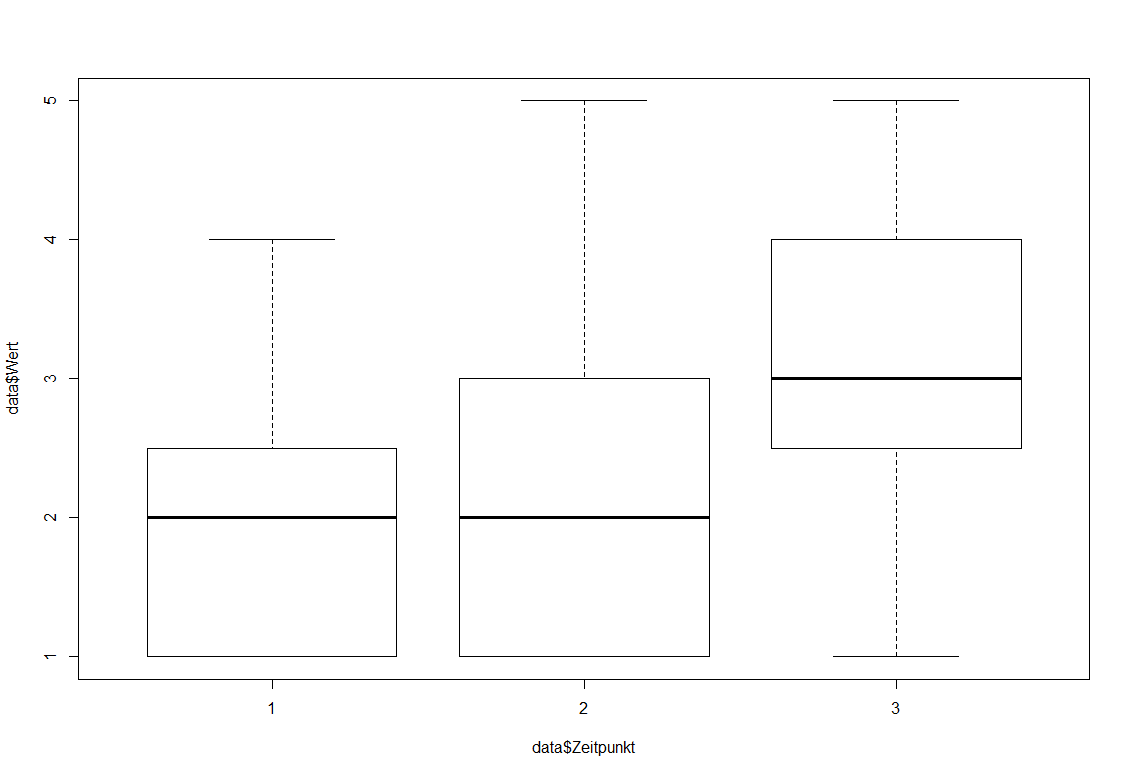
Hierzu lasse ich mir mit der boxplot()-Funktion die Messwerte (data$Wert) je Zeitpunkt (Data$Zeitpunkt) ausgeben. „data$“ steht lediglich davor, weil ich die Daten nicht attached habe und ich sie aus dem Dataframe namens „data“ beziehe. Das $ verknüpft Dataframe und Variablenname.
boxplot(data$Wert~data$Zeitpunkt)
Im Ergebnis ist erkennbar, dass im Zeitpunkt 3 die Box deutlich über der Boxen aus den Zeitpunkten 1 und 2 liegt. Eine Anpassung von Boxplots zeige ich hier ausführlicher.
3.2 Deskriptive Statistiken
Hier kann mittels des „dplyr„-Pakets und dessen summarize()-Funktion sowie Piping in Verbindung mit der group_by()-Funktion gearbeitet werden. Ich lasse mir lediglich den Median sowie das 1. Quartil und 3. Quartil ausgeben:
library(dplyr)
data %>%
group_by(Zeitpunkt) %>%
summarize(Mdn = median(Wert),
Q1 = quantile(Wert, probs = .25),
Q3 = quantile(Wert, probs = .75)) %>%
as.data.frame()
Das Ergebnis ist:
Zeitpunkt Mdn Q1 Q3
1 1 2 1.0 2.5
2 2 2 1.0 3.0
3 3 3 2.5 4.0
Erkennbar ist, dass sich die Mediane im Zeitpunkt 1 und 2 zwar gleichen, in Verbindung mit den Quartilen bzw. dem Boxplot ist aber erkennbar, dass im Zeitpunkt 2 die Streuung nach oben hin zugenommen hat. Zeitpunkt 3 zeigt eine weitere Zunahme des Testscores, was anhand aller Lageparameter (Median, Quartil 1 und Quartil 3) erkennbar ist.
4 Durchführung und Interpretation des Friedman-Tests in R
4.1 Friedman-Test berechnen
Zur Berechnung des Friedman-Tests braucht es keine zusätzlichen Pakete. Man verwendet einfach die friedman.test()-Funktion:
- Als erstes Argument ist die Variable mit den Messwerten anzugeben.
- Als zweites Argument ist die Variable anzugeben, die die Zeitpunkte enthält
- als drittes Argument ist die Variable anzugeben, die die Beobachtungsobjekte identifiziert – typischerweise eine einfache eindeutige Probanden-ID
Der Einfachheit wegen heißen meine Variablen im Code analog dazu:
friedman.test(data$Wert, data$Zeitpunkt, data$Proband)
Nachfolgend erhält man folgenden Output. Wichtig ist hier eigentlich nur der p-Wert.
Friedman rank sum test
data: data$Wert, data$Zeitpunkt and data$Proband
Friedman chi-squared = 22.372, df = 2, p-value = 1.387e-05
Der p-Wert ist in wissenschaftlicher Schreibweise dargestellt. 1.387e-05 schiebt das Komma um 5 Stellen nach links. Demzufolge ist der p-Wert 0.00001387 und demnach sehr klein. Die Nullhypothese keines Unterschiedes über die Zeitpunkte hinweg kann hiermit verworfen werden.
Da beim Friedman-Test aber ja mindestens drei Zeitpunkte existieren, ist noch unklar, zwischen welchen Zeitpunkten signifikante Unterschiede bestehen. Hierzu bedarf es der Berechnung von post-hoc-Tests.
4.2 Effektstärke Kendall’s ω berechnen
Eine Effektstärke für den Friedman-Test selbst wird zwar nicht zwingend benötigt, kann aber eine gute Basis für andere Studien sein, die im Vorfeld eine Stichprobengröße ermitteln müssen. Daher kann die Effektstärke Kendall’s ω (Omega) berechnet werden. Aufgrund der optischen Ähnlichkeit wird es häufig auch als Kendall’s W bzw. Kendall’s w bezeichnet. Die Berechnung erfolgt über die friedman_effsize()-Funktion des „rstatix„-Pakets:
install.packages("rstatix")
library(rstatix)
friedman_effsize(data, Wert~Zeitpunkt | Proband)
Das führt zu folgendem Ergebnis:
.y. n effsize method magnitude
*
1 Wert 15 0.746 Kendall W large
Im Beispiel liegt eine Effektstärke Kendall’s ω von 0.746 vor. In der Funktion wird auch direkt eine Einordnung als „groß“ vorgenommen.
Hierzu dienen wurden die Grenzen von Cohen (1992), S. 157 verwendet:
- ab ω = 0,1 liegt ein kleiner Effekt vor,
- ab ω = 0,3 liegt ein mittlerer Effekt vor und
- ab ω = 0,5 liegt ein großer Effekt vor.
Sollten bereits Studien existieren oder fachspezifische Grenzen existieren, sind diese für eine Einordnung des Ergebnisses vorzuziehen.
5 Durchführung und Interpretation der post-hoc-Tests
5.1 Post-Hoc-Tests für den Friedman-Test in R
Zunächst ist anzumerken, dass keine vollständige Klarheit herrscht, welche post-hoc-Tests zu rechnen sind. Daher einen Schritt zurück: worum geht es bei den post-Hoc-Tests beim Friedman-Test überhaupt?
Das Ziel ist, herauszufinden, zwischen welchen Zeitpunkten Unterschiede hinsichtlich der abhängigen Variable bestehen. Es werden also paarweise Vergleiche aller Zeitpunkte miteinander gerechnet.
Hier beginnt nun allerdings die Schwierigkeit, da es keine eindeutige Empfehlung gibt, welcher paarweise Vergleich der „richtige“ ist.
Das „PMCMRplus„-Paket bietet 5 mögliche Funktionen:
- Eisinga et al. (2017): frdAllPairsExactTest()
- Conover’s test: frdAllPairsConoverTest()
- Nemenyi’s test: frdAllPairsNemenyiTest()
- Miller et al.: frdAllPairsMillerTest()
- Siegel-Castellan: frdAllPairsSiegelTest()
Ich persönlich tendiere zu der exakten p-Wert-Methode von Eisinga et al. (2017), vor allem wegen der geringeren Beta-Fehlerwahrscheinlichkeit.
Die Alphafehlerwahrscheinlichkeit kann mit der entsprechenden Fehlerkorrektur angepasst werden. Zur Wahl stehen „holm“, „hochberg“, „hommel“, „bonferroni“, „BH“, „BY“, „fdr“ und „none“.
Ich führe exemplarisch die Berechnung mit Bonferroni-Korrektur durch. Je nach Fachdisziplin sind unterschiedliche Korrekturen üblich und anzuwenden.
install.packages("PMCMRplus")
library(PMCMRplus)
frdAllPairsExactTest(data$Wert, data$Zeitpunkt, data$Proband,
p.adjust.method = "bonferroni")
Das Ergebnis, also lediglich die p-Werte, werden in einer kleinen Matrix ausgegeben, die alle Zeitpunkte jeweils miteinander vergleicht.
Beispiel: Der Vergleich der Zeitpunkte 1 und 2 zeigt einen p-Wert von 0.714.
Pairwise comparisons using Eisinga, Heskes, Pelzer & Te Grotenhuis
all-pairs test with exact p-values for a two-way balanced complete block design
data: y, groups and blocks
1 2
2 0.714 -
3 7.5e-05 0.021
P value adjustment method: bonferroni
- Die p-Werte werden nun mit dem vorher festgelegten Alphaniveau verglichen.
- Typischerweise werden hier 5%, also 0.05 angesetzt. Nach Wasserstein (2016) ist eine feste Alphagrenze aber nicht sonderlich hilfreich, geschweige denn notwendig.
- In jedem Falle haben die Zeitpunkte 1-3 und die Zeitpunkte 2-3 hinreichend kleine p-Werte mit 7.5e-05 (= 0000075) und 0.021.
Schließlich ist noch interessant, wie groß der Unterschied zwischen den Zeitpunkten ist – allein anhand der oben erstellten Boxplots ist eine Abschätzung zwar möglich, aber schwer. Zudem sollte eine Standardisierung der Unterschiede zur Vergleichbarkeit durchgeführt werden, was nachfolgend gezeigt wird.
5.2 Effektstärke für Post-Hoc-Tests für den Friedman-Test in R
Ergänzend oder vielmehr hauptsächlich sollten Effektstärken für die post-hoc-Test für einen signifikanten Friedman-Test gerechnet werden. Leider gibt es keine fertige Funktion hierfür und ich habe mir einige Gedanken dazu gemacht, bin aber natürlich offen für Diskussionen.
- Prinzipiell kann eine Effektstärke r analog zum Wilcoxon-Test für abhängige Stichproben berechnet werden.
- Formel:
![\[ r = \lvert \frac{z}{\sqrt{N}}\\]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-e2f7245620b11eef06c19e92f062c414_l3.png "Rendered by QuickLaTeX.com")
- Der z-Wert wird durch die Wurzel der Stichprobengröße, also vorhandene Beobachtungen der Vergleiche geteilt. Allerdings haben wir durch die post-hoc-Tests nur p-Werte erhalten.
Ich kann aber jeden der in den paarweisen Vergleichen ermittelten p-Werten in eine standardisierte Teststatistik (meist als z geschrieben) transformieren. - Dazu verwendet man den halbierten p-Wert in der qnorm()-Funktion.
Halbiert deshalb, weil nur bei einseitigen Tests der ursprüngliche p-Wert verwendet wird und im Falle von Post-hoc-Tests zweiseitig getestet wird. - Da ich zwei p-Werte habe, die niedrig genug sind, werde ich z1 und z2 mit den halbierten p-Werten berechnen.
- ACHTUNG: Es sollten für die Berechnung die unkorrigierten p-Werte verwendet werden, also in frdAllPairsExactTest() in Abschnitt 5.1 mit p.adjust.method = „none“ gearbeitet werden.
- Die Entscheidung, welcher paarweise Vergleich als „signifikant“ erachtet wird, wird natürlich nicht geändert und die in 5.1 verwendeten p-Werte behalten hierfür ihre Gültigkeit.
frdAllPairsExactTest(data$Wert, data$Zeitpunkt, data$Proband,
p.adjust.method = "none")
# unkorrigierte p-Werte
1 2
2 0.2379 -
3 2.5e-05 0.0069
Nun kann ich die Transformation mit der qnorm()-Funktion vornehmen:
z1 <- qnorm(0.0069/2)
z2 <- qnorm(2.5e-05/2)
Und schließlich kann ich die Formel für die Effektstärke r verwenden, lasse mir im Vorfeld noch die Anzahl der Beobachtungen in n speichern.
n <- friedman_test(data, Wert~Zeitpunkt | Proband)$n
# Formel: r = z/sqrt(n)
r1 <- z1/sqrt(n)
r2 <- z2/sqrt(n)
Das führt zu folgenden Ergebnissen:
> r1
[1] -1.088257
> r2
[1] -0.6975585
Bei Effektstärken wird das Minuszeichen ignoriert, daher werden nur positive Werte verwendet und angegeben.
- Im Beispiel hat der Unterschied zwischen Zeitpunkt 1 und Zeitpunkt 3 eine Effektstärke von r = 1.09.
- Die Effektstärke für den Unterschied zwischen Zeitpunkt 1 und 3 beträgt r = 0.7.
Laut Cohen: Statistical Power Analysis for the Behavioral Sciences (1988), S. 79-81 bzw. Cohen (1992), S. 157 sind die Effektgrenzen:
- ab r = 0,1 (schwach)
- ab r = 0,3 (mittel)
- ab r = 0,5 (stark).
Im vorliegenden Beispiel sind beide Effektstärken groß, da 1.09 > 0,5 und 0.7 > 0,5. Es handelt sich also jeweils um einen großen Effekt zwischen Zeitpunkt 1 und 3 sowie zwischen Zeitpunkt 2 und 3 hinsichtlich der Testvariable
6 Reporting
Zum Berichten empfiehlt sich:
- der Friedman-Test selbst mit Chi²-Wert, Freiheitsgraden, p-Wert und Kendall's ω,
- signifikante post-hoc-Tests mit p-Werten, und Effektstärke r und Median pro Zeitpunkt
- Einordnung der Effektstärken
Der Friedman-Test zeigte signifikante Unterschiede des Testscores über die Zeit (Chi² (2) = 22.37, p = 1.387e-05, ω = 0.746).
Zwischen Zeitpunkt 1 (Mdn = 2) und Zeitpunkt 2 (Mdn = 2), p = 0.021, r = 0.7 sowie Zeitpunkt 2 (Mdn = 2) und Zeitpunkt 3 (Mdn = 3), p < 0.001, r = 1.09 sind Unterscheide beobachtbar.
Nach Cohen (1992) sind beide Unterschiede groß.
7 Videotutorials





8 Literatur
- Cohen, J. A power primer. Psychological bulletin 112.1 (1992): 155-159.
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences: Jacob Cohen. New York, N.J: Psychology Press.
- Eisinga, Rob, et al. "Exact p-values for pairwise comparison of Friedman rank sums, with application to comparing classifiers." BMC bioinformatics 18.1 (2017): 1-18.
- Wasserstein, R. L., & Lazar, N. A. (2016). The ASA statement on p-values: context, process, and purpose. The American Statistician, 70(2), 129-133.
9 Datensatz


