Inhaltsverzeichnis
1 Einleitung: Was ist eine Explorative Faktorenanalyse (EFA)?
Das Ziel einer EFA ist, aus vielen Einzelitems übergeordnete Dimensionen – sogenannte Faktoren – zu identifizieren. Es wird auch als Verfahren zur Dimensionsreduktion verwendet bzw. bezeichnet.
Eine EFA dient also zur Reduktion von Daten, ist aber immer noch ein exploratives Vorgehen und keinesfalls mit einer konfirmatorischen Faktorenanalyse (kurz: KFA) gleichzusetzen.
Ein typisches Beispiel einer EFA: Ich habe 11 Items zur Kundenzufriedenheit.
- Das Produkt/Die Dienstleistung erfüllt meine Erwartungen in vollem Umfang.
- Die Qualität des Produkts/der Dienstleistung ist ausgezeichnet.
- Das Produkt/Die Dienstleistung ist sehr zuverlässig.
- Ich bin mit der Funktionalität des Produkts/der Dienstleistung sehr zufrieden.
- Der Kundenservice ist sehr freundlich und hilfsbereit.
- Meine Anfragen wurden schnell und effizient bearbeitet.
- Die Mitarbeiter des Kundenservice sind sehr kompetent.
- Probleme wurden zu meiner vollsten Zufriedenheit gelöst.
- Der Preis des Produkts/der Dienstleistung ist angemessen.
- Ich habe das Gefühl, einen guten Wert für mein Geld erhalten zu haben.
- Das Produkt/Die Dienstleistung ist jeden Cent wert.
Alle Fragen wurden auf einer 5-stufigen Skala beantwortet (von „stimme gar nicht zu“ bis „stimme voll zu“) von 180 Befragten beantwortet.
Statt jeden Aspekt einzeln zu betrachten, möchte man wissen, ob es dahinter vielleicht nur 2 oder 3 übergeordnete Dimensionen, wie z. B. „Produkt-/Dienstleistungsqualität“, „Service- und Supportqualität“ oder “Preis-Leistungsverhältnis”?
2 Durchführung einer explorativen Faktorenanalyse in SPSS
Über das Menü: Analysieren > Dimensionsreduktion > Faktorenanalyse
Hier werden alle Items der zu prüfenden Skala in das Feld “Variablen” geschoben.

2.1 Deskriptive Statistiken und Eignungstests
Beim Button „Deskriptive Statistik“ werden zusätzlich “Koeffizienten”, “Signifikanzniveau”, Invers und KMO und Bartlett-Test angefordert.

Die Korrelationen geben uns nachher einen ersten Eindruck über die Eignung der Items im Rahmen einer EFA.
Der KMO-Wert (Kaiser-Meyer-Olkin) geht einen Schritt weiter und sagt uns in einer Zahl, abgestuft, etwas zur Eignung. Der Bartlett-Test tut an sich dasselbe, weswegn beides über nur einen Button angefordert wird.
2.2 Extraktionsmethoden
Einer, wenn nicht sogar DER wichtigste Button ist „Extraktion“.

Es gibt verschiedene Methoden: im wesentlichen werden nur A) Hauptkomponenten und B) Hauptachsen-Faktorisierung verwendet.
Beide führen typischerweise zu qualitativ ähnlichen Ergebnissen. Dennoch kurz zu den Unterschieden:
- A) Die Hauptkomponentenanalyse fasst die Informationen aus korrelierten beobachteten Items zu neuen, unkorrelierten Hauptkomponenten zusammen. Sie ist primär für die Datenreduktion konzipiert und darauf ausgelegt, die gesamte Varianz jedes einzelnen Items durch diese Komponenten zu erklären.
- B) Die Hauptachsenanalyse versucht, die gemeinsame Varianz korrelierter beobachteter Items zu erklären, die von zugrunde liegenden, nicht direkt messbaren (latenten) Faktoren verursacht wird. Sie ist primär darauf ausgelegt, die Struktur dieser latenten Faktoren aufzudecken, indem spezifische Varianz und Messfehler der einzelnen Items von der gemeinsamen Varianz getrennt werden.
Ich wähle in meinem Beispiel Hauptachsenanalyse, weil die Skala latente Faktoren („Produkt-/Dienstleistungsqualität“, „Service- und Supportqualität“ oder “Preis-Leistungsverhältnis”) darstellt.
Nach der Wahl der Extraktionsmethode geht es weitern bei den Einstellungen: Screeplot aktivieren – dieser ist eine visuelle Hilfe zur Identifikation der optimalen Anzahl an Faktoren.

Bei Extrahieren bleibt “Basierend auf Eigenwert” angehakt und größer 1 – das ist ein typischer Ausgangspunkt. Sollte man im Vorfeld wissen, wie viele Faktoren extrahiert werden sollen, kann dies hier auch angegeben werden.
Für mein Beispiel belasse ich das Eigenwertkriterium von 1 zur Faktorextraktion.
2.3 Rotationsmethoden
Als nächstes geht es zum Button „Rotation“.

Auch hier ist es wichtig, die richtige Rotationsmethode zu wählen. Grundlegend gibt es orthogonale und oblique Rotation.
- Varimax, quartimax und equamax sind orthogonale Rotationsmethoden
- oblimin und promax sind oblique Rotationsmethoden.
Die Entscheidung hängt hier von der (angenommenen) Korrelation der Faktoren ab. Orthogonale Rotation nimmt keine Korrelation zwischen den Faktoren an. Anders ausgedrückt: die Items laden auf einen Faktor maximal, auf andere möglichst minimal.
Bei obliquer Rotation wird davon ausgegangen, dass die Faktoren korrelieren (dürfen) – was bei einer darüber liegenden Skala zu erwarten ist.
Im Beispiel ist es eher wahrscheinlich, dass die Faktoren Produkt-/Dienstleistungsqualität“, „Service- und Supportqualität“ und “Preis-Leistungsverhältnis” korrelieren werden. Ich wähle also hier oblique Rotation, oblimin.
Die Interpretation der Ergebnisse ist bis auf wenige Ausnahmen von der Art der Rotation unabhängig.
2.4 Ausblenden kleiner Ladungen
Schließlich noch kurz zum Button „Optionen“.

- Kleine Koeffizienten mit Ladungen kleiner als 0.3 oder auch 0.4 können unterdrückt werden, um eine übersichtlichere Tabelle zu erhalten.
- Die Sortierung nach Größe kann hilfreich sein, wenn die Items allerdings in einer bestimmten Reihenfolge sind, kann dies verwirrend sein.
- > 0.90 – „marvelous“ – wunderbar
- > 0.80 – „meritorious“ – (sehr) gut, wörtlich: „lobenswert“
- > 0.70 – „middling“ – gut, wörtlich: mittelmäßig
- > 0.60 – „mediocre“ – durchschnittlich, wörtlich: mittelmäßig
- > 0.50 – „miserable“ – miserabel
- < 0.50 - "unacceptable" - inakzeptabl
- Bei orthogonaler Rotation sind es die Faktorenmatrix und die rotierte Faktorenmatrix.
- Bei obliquer Rotation sind es die Faktorenmatrix, Mustermatrix und die Strukturmatrix.
- 4 Items auf Faktor 1 laden,
- 3 Items auf Faktor 2 laden und
- 4 Items auf Faktor 3 laden
- Ladungen > .40 gelten als substanziell, Items mit geringeren Ladungen sind für die jeweiligen Faktoren nicht relevant.
- Ein Item lädt Idealerweise hoch auf einen Faktor und gering bis gar nicht auf alle anderen Faktoren.
- Hohe negative Ladungen können ebenfalls aufschlussreich sein – sofern sie nicht ausgeblendet wurden – da sie invers formuliert möglicherweise auch zum Faktor hinzugenommen werden können. Das sollte im Vorfeld allerdings schon geschehen sein.
- Doppelladungen oder Querladungen (> .40 auf mehrere Faktoren) sind problematisch.
- Wenn die Differenz zwischen den Ladungen hoch ist, wird das Item den Faktor zugeordnet, auf das es am stärksten lädt.
- Ist die Differenz allerdings gering, ist eine eindeutige Zuordnung schwierig und ein Ausschluss des Items und erneute Rechnung empfohlen.
- Die Items mit Ladungen auf denselben Faktor ergeben zusammengenommen das darüberliegende Konstrukt. Das ergibt sich meist aus den Itemformulierungen – ich wusste es im Beispiel im Vorfeld schon, kann es hier aber auch ganz gut ableiten.
- Field, Andy (2018), Discovering Statistics Using IBM SPSS Statistics, SAGE.
- Kaiser, H. F. (1974). An index of factorial simplicity. psychometrika, 39(1), 31-36.
- Lantz, B. (2013). The large sample size fallacy. Scandinavian journal of caring sciences, 27(2), 487-492.
3 Interpretation der explorativen Faktorenanalyse in SPSS
Der Output ist recht lang und wird in den nachfolgenden 6(+1) Unterkapiteln erläutert
3.1 Korrelationsmatrix und inverse Korrelationsmatrix
Zunächst hat man eine Korrelationsmatrix – mehr oder weniger groß, je nach Anzahl der Items.

>KLICK ZUM VERGRÖßERN DER TABELLE<
Die Matrix ist in zwei Teile unterteilt – oben die Korrelation, unten die einseitige Signifikanz. Das kann als erste Orientierung dienen, wenn inhaltlich ähnliche Items, die später (hoffentlich) zu Faktoren zusammengefasst werden, positiv miteinander korrelieren.
Beispielsweise erkennt man, dass die ersten vier Items allesamt mit ca. 0,5 miteinander korrelieren. Die nächsten vier Items korrelieren grob zwischen 0,3 und 0,5 und die letzten drei Items korrelieren mit 0,6 bis 0,7. Mit anderen Items ist die jeweilige Korrelation eher gering.
Die Signifikanzen darunter können als grober Anhaltspunkt dienen, brauchen aber nicht weiter beachtet werden.
Noch ein, zwei Sätze zur inversen Korrelationsmatrix.

>KLICK ZUM VERGRÖßERN DER TABELLE<
Die inverse Korrelationsmatrix sollte diagonal sein, also hohe Werte auf und geringe Werte abseits der Diagonalen aufweisen. Im Bild sind die Werte auf der Diagonalen rot mit einem Viereck umrandet. Hier ist gut erkennbar, dass dies deutlich der Fall ist, weswegen sich eine Faktorenanalyse anbietet.
3.2 KMO und Bartlett-Test
Als nächstes liefert der SPSS-Output den KMO-Wert und den Bartlett-Test:
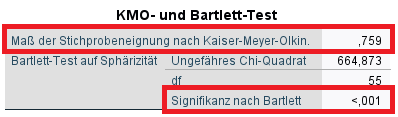
3.2.1 KMO – Kaiser-Meyer-Olkin
KMO kann Werte zwischen 0 und 1 annehmen und drückt aus, wie geeignet die Items bzw. die Daten generell für eine explorative Faktorenanalyse sind.
Vereinfacht gesagt ist er ein Maß, dafür, ob die Korrelationen zwischen Items hinreichend gut sind und sich hieraus Faktoren ableiten lassen.
Zur Einordnung des KMO-Wertes wird auf Kaiser (1974), S. 35 Bezug genommen:
Zusammengefasst: ab 0.6 ist alles im grünen Bereich, darunter ist Vorsicht geboten.
In meinem Beispiel ist mit 0.759 alles ok, ich kann also mit der Extraktion von Faktoren rechnen.
3.2.2 Bartlett-Test auf Sphärizität
Direkt darunter findet sich der Bartlett-Test auf Sphärizität. Dieser testet die Nullhypothese, ob die Korrelationsmatrix (von oben) von der Einheitsmatrix abweicht.
Das sollte der Fall sein, da eine Einheitsmatrix bedeutet, dass auf der Diagonalen stets 1en stehen – die Items korrelieren mit sich selbst mit 1 und zusätzlich, dass jedes Item mit allen anderen Items mit 0, also überhaupt nicht korreliert.
Salopp gesagt, prüft der Bartlett’s Test also, ob es genug korrelative Zusammenhänge zwischen Items gibt und sich eine explorative Faktorenanalyse lohnt. Bei hinreichend kleinem p-Wert ist dies gegeben – ich verwende nicht (mehr) den Begriff „signifikant“, was ich in diesem Artikel ausführlich erkläre.
Aber Achtung, Signifikanztests haben bei großen Stichproben automatisch kleine p-Wert (vgl. Lantz (2003)), weswegen man den Bartlett-Test nicht isoliert, sondern immer zusammen mit dem KMO-Wert betrachten sollte. Zusätzlich kann noch die Korrelationsmatrix sowie die inverse Korrelationsmatrix zur Beurteilung der Eignung einer explorativen Faktorenanalyse herangezogen werden.
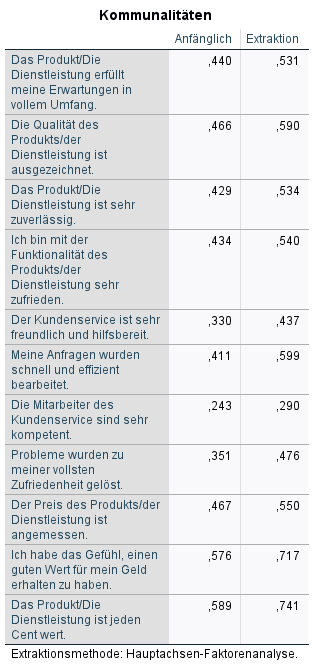
Nachdem wir festgestellt haben, dass wir mit der Faktorenanalyse fortfahren können, schauen wir uns die nächste Tabelle an: Kommunalitäten.
3.3 Kommunalitäten
Die Kommunalität eines Items ist die Summe der quadrierten Ladungen dieses Items über alle extrahierten Faktoren hinweg. Sie zeigt, in welchem Ausmaß ein Item durch alle extrahierten Faktoren erklärt wird, also wie gut das Item in der gesamten Faktorlösung repräsentiert wird. In der Spalte „Extraktion“ steht also letztlich die erklärte Varianz in Prozent des Items durch alle extrahierten Faktoren, also wie gut das Item wiederum durch alle Faktoren erklärt wird. Das ist nicht weiter berichtenswert, aber ein guter Anhaltspunkt, ob es “problematische” Items geben könnte.
Zur Beurteilung wird sich auf die zweite Spalte der Tabelle „Kommunalitäten“ bezogen, also auf die Spalte „Extraktion“. Hier hält man Ausschau nach Werten, die niedrig sind bzw. deutlich niedriger sind als Werte anderer Items. Das ist im Beispiel beim Item „Die Mitarbeiter des Kundenservice sind sehr kompetent.“ mit 0.290 der Fall. Dieses Item könnte also möglicherweise in den noch zu betrachtenden Lösungen eine möglicherweise niedrigere Ladung auf einen Faktor aufweisen.
3.4 Erklärte Gesamtvarianz & Eigenwerte
In der Tabelle „Erklärte Gesamtvarianz“ finden wir genau das – die erklärte Gesamtvarianz sowie die Eigenwerte der Faktoren.
Alle Faktoren mit Eigenwert > 1 gelten nach Kaisers Kriterium als sinnvoll – es wurde ja auch bei der Extraktionsmethode definiert (siehe Punkt 2.2).
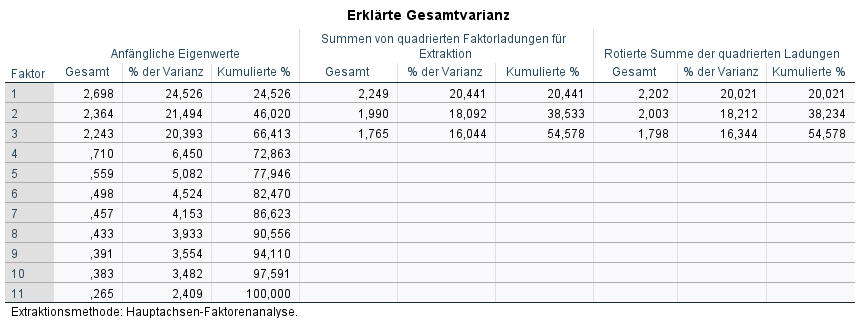
In meinem Fall ist deutlich erkennbar, dass 3 Faktoren gebildet werden sollten, da deren Eigenwerte jeweils über 1 liegen. Zusammen genommen erklären die 3 zu bildenden Faktoren 66.413% der Varianz aller Items.
Aber Achtung: Die Eigenwertregel von 1 ist nicht in Stein gemeißelt und kann zu viele oder zu wenige Faktoren liefern, weswegen zusätzlich der sog. Scree-Plot zu prüfen ist.
3.5 Screeplot
Der Scree-Plot findet sich direkt darunter und hier wird der sog. „Knick“ oder Ellenbogen gesucht.

Alle Faktoren vor dem Knick – bei mir 3 – gelten als sinnvoll bzgl. der Extraktion. Typischerweise kommt der Screeplot zum selben Ergebnis wie die Tabelle erklärte Gesamtvarianz, wenn aber der Eigenwert erst unter 1 deutlich abfällt, ist die strenge Auslegung dieser harten Grenze überdenkenswert.
3.6 Rotierte Matrizen: Struktur finden und Faktoren benennen
Je nach Rotationsmethode (siehe Abschnitt 2.3) erhält man nach dem Screeplot unterschiedliche Matrizen.
Für die bessere Lesbarkeit und Interpretierbarkeit rate ich allerdings zur rotierten Komponentenmatrix bzw. Muster-/Strukturmatrix.
Da SPSS, sofern nicht anders angegeben (Extraktionsmethoden in 2.2), anhand des Eigenwertes entscheidet, wie die Komponentenmatrix zustande kommt, sind es hier die 3 oben schon erkannten Komponenten bzw. Faktoren.
Ich beginne zunächst mit der orthogonalen Rotation und zeige kurz die Interpretation der von SPSS ausgegebenen Rotierten Faktorenmatrix.
3.6.1 Orthogonale Rotation – Rotierte Faktorenmatrix
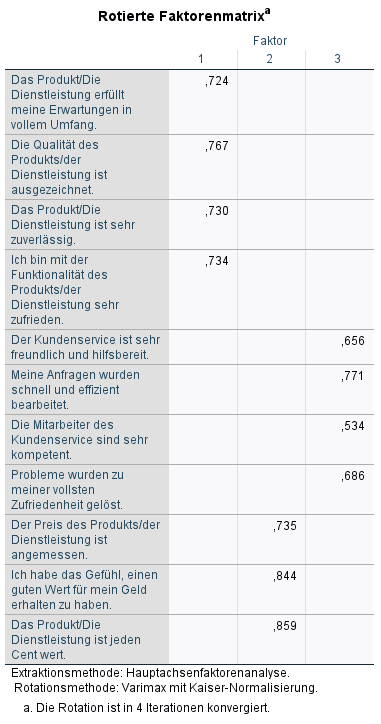
Man sieht hier jeweils welche Items auf welche Faktoren wie stark laden. Je höher die Ladung, desto eher lädt das Item auf diesen Faktor.
Hier ist erkennbar, dass:
Hinweis: ich habe mir Ladungen unter 0,4 ausblenden lassen, damit es etwas übersichtlicher ist.
Inhaltlich sehe ich auch, dass Faktor 1 die Produktzufriedenheit darstellt, Faktor 2 das Preis-Leistungsverhältnis und Faktor 3 die Dienstleitungszufriedenheit.
In der Realität ist es natürlich nicht ganz so eindeutig, wie in meinem konstruierten Beispiel.
3.6.2 Oblique Rotation – Mustermatrix, Strukturmatrix


Zur Erinnerung: Je höher die Ladung, desto eher lädt das Item auf diesen Faktor. Hier erkennt man ebenfalls, dass ich 4 Items habe, die auf Faktor 1 laden, 3 Items, die auf Faktor 2 laden und 4 Items, die auf Faktor 3 laden (Ladungen unter 0,4 sind ausgeblendet).
Inhaltlich bedeutet das auch, dass Faktor 1 die Produktzufriedenheit darstellt, Faktor 2 das Preis-Leistungsverhältnis und Faktor 3 die Dienstleitungszufriedenheit.
Worin unterscheiden sich Mustermatrix und Strukturmatrix?
Die Mustermatrix zeigt direkte Effekte der Items auf die Faktoren. Die Strukturmatrix zeigt neben den direkten Effekten auf Faktoren auch die indirekten Effekte von Items, welche über Korrelationen mit anderen Faktoren zustande kommen. Typischerweise wird die Mustermatrix primär interpretiert, weil eben die Korrelationen von Items mit anderen Faktoren dort nicht beachtet werden bzw. die Mustermatrix darum bereinigt ist und es nicht immer identisch ist, wie in meinem Beispiel. Dennoch kann die Strukturmatrix ein Gesamtbild der Korrelationen zwischen Items und Faktoren liefern, inklusive aller direkten und indirekten Beziehungen.
3.6.3 Interpretationshilfen
In vielen Beispielen ist es nicht so eindeutig, daher hier ein paar Grundsätze:
3.7 Korrelationsmatrix für Faktoren (nur bei obliquen Rotationen)

Die Faktorenkorrelationsmatrix gibt es nur bei der obliquen Rotationsmethode und zeigt die Korrelationen zwischen den Faktoren.
Im Beispiel ist erkennbar, dass ich hier recht nah an einer Identitätsmatrix bzw. Einheitsmatrix bin – die Fakotren korrelieren mit sich selbst mit 1 und Korrelationen abseits der Diagonalen sind sehr klein. Die oben getroffene Annahme, dass die Faktoren korrelieren und ich infolgedessen eine oblique Rotation wählen sollte, hat sich also nicht erhärtet.
Folglich könnte ich eine erneute explorative Faktorenanalyse, diesmal mit orthogonaler Rotation wie varimax rechnen. Qualitativ sollte sich hierbei nichts ändern.
4 Nach der explorativen Faktorenanalyse
Im Anschluss an eine explorative Faktorenanalyse kann man in SPSS direkt fortfahren, indem man die Reliabilität der (Sub-)Skalen bildet und diese (Sub-)Skalen aus den Items bildet.
5 Literatur



