

1 Ziel des t-Test bei abhängigen Stichproben in SPSS (gepaarter t-Test)
Der t-Test für abhängige Stichproben (auch: gepaarter t-Test oder verbundener t-Test) prüft, ob bei zwei abhängigen bzw. verbundenen Stichproben die Mittelwerte unterschiedlich sind. Abhängig, verbunden bzw. gepaart bedeutet, dass dieselben Untersuchungsobjekte zu zwei Zeitpunkten befragt/vermessen wurden.
Bei unabhängigen Stichproben ist der t-Test für unabhängige Stichproben zu rechnen. Wie der Test in Excel zu rechnen ist, zeigt dieser Artikel. Für R empfehle ich diesen Artikel.
Allgemeine Erklärungen zum t-Test bei abhängigen Stichproben
2 Voraussetzungen des t-Test bei abhängigen Stichproben in SPSS
Die wichtigsten Voraussetzungen sind:
- zwei voneinander abhängige Stichproben/Gruppen
- metrisch skalierte y-Variable
- normalverteilte Residuen innerhalb der Gruppen (ab Gruppengröße von >30 unproblematisch)
- Achtung: Mindeststichprobengröße bedenken – über eine Poweranalyse zu ermitteln
3 Durchführung des t-Test bei abhängigen Stichproben in SPSS
Über das Menü in SPSS: Analysieren -> Mittelwerte vergleichen -> T-Test bei verbundenen Stichproben

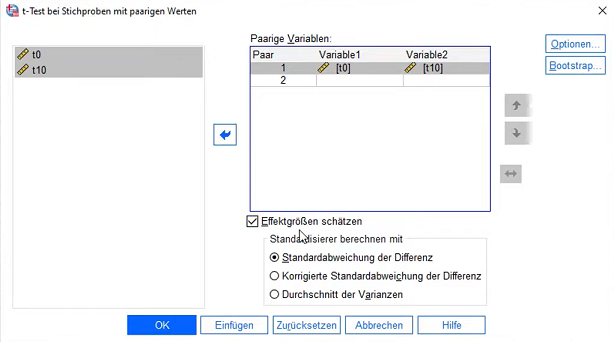
Als Variablen sind Messwerte zum Zeitpunkt 1 als Variable 1 und Messwerte zum Zeitpunkt 2 als Variable 2 auszuwählen.
Optional: Unter Optionen 95% Konfidenzintervall und „Fallausschluss Test für Test“.
4 Interpretation des t-Test bei abhängigen Stichproben in SPSS


1. Ein erster Blick lohnt sich immer auf die Mittelwerte (18,7647 und 27,6471) in der Tabelle „Statistik bei gepaarten Stichproben“. Dadurch gewinnt man einen ersten Eindruck. Im Beispiel hat sich der Mittelwert recht deutlich erhöht, was ein erster wichtiger Hinweis ist.
2. Die Mittelwertdifferenz (-8,8235) ist in der Tabelle „Test bei gepaarten Stichproben“ angegeben und berechnet sich stets aus der Differenz von Mittelwert zum Zeitpunkt 1 und Mittelwert zum Zeitpunkt 2. Hier wären das 18,7647-27,6471 = -8,8235.
3. Schließlich muss noch die Frage beantwortet werden, ob diese Mittelwertdifferenz, also Veränderung über die Zeit signifikant ist. Dazu wird ebenfalls in der Tabelle „Test bei gepaarten Stichproben“ geschaut. Hierzu prüft man Sig. (2-seitig). Ist sie kleiner als Alpha=0,05 (bzw. euer vorher definiertes Alpha), geht man von statistisch signifikanten Unterschieden hinsichtlich der Mittelwerte zwischen den Zeitpunkten aus.
Der Unterschied wäre außerdem signifikant, wenn das 95%-Konfidenzintervall (hier nicht dargestellt) den Wert „0“ nicht beinhaltet, also beide Intervallgrenzen positiv oder negativ sind
ACHTUNG: Hat man bereits eine Vermutung, dass z.B. eine Stichprobe einen höheren/niedrigeren Wert hat, ist dies eine gerichtete Hypothese und man muss 1-seitig testen. Dazu halbiert man den bei Sig. (2-seitig) erhaltenen Wert und prüft jenen auf Signifikanz.
Ist die Veränderung zwar signifikant, allerdings entgegen der Hypothese, kann die Hypothese entsprechend NICHT bekräftigt werden.
4. Schließlich muss nach einem signifikanten Unterschied noch die Effektstärke ermittelt werden. Die Effektstärke beschreibt, wie stark sich die Testvariable zwischen beiden Zeitpunkten unterscheidet und dient als standardisierte Größe zur Einordnung von Unterschieden. Die Effektstärke (Cohen’s d und Hedges‘ g) wird von SPSS ab Version 27 ausgegeben:
Im Normalfall wird Cohen’s d berichtet. Sollte N<20 sein, ist Hedges' g vorzuziehen, da Cohen's d leicht verzerrt ist (Rosenstein (2019), S. 73). Da man selten weniger als 20 Beobachtungsobjekte hat, berichte ich hier trotz N<20 ausnahmsweise Cohen's d.


Hier ist ablesbar: d=-1,636. Da Effektstärken immer positiv berichtet und interpretiert werden, ist d=1,636.
In früheren Versionen von SPSS muss die Berechnung manuell erfolgen. Dazu dient die folgende Formel mit t und der Wurzel der Stichprobengröße N. Das Ergebnis ist identisch zur SPSS-Ausgabe.
![\[ d=\frac{|t|}{\sqrt{N}}= \frac{|-6,744|}{\sqrt{17}} = 1,635781506 \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-d0c89a34174a73d040d6312b4dcbe990_l3.png "Rendered by QuickLaTeX.com")

- ab 0,2 klein,
- ab 0,5 mittel und
- ab 0,8 stark.
5 Reporting des gepaarten t-Tests
Verglichen mit vor dem Training (M = 18,76; SD = 9,11) schaffen Probanden nach dem Training (M = 27,65; SD = 13,28) eine signifikant höhere Anzahl Wiederholungen, t(16) = 6,74; p < 0,001; d = 1,64. Nach Cohen (1992) ist dieser Unterschied groß.
6 Tipp zum Schluss
Findest du die Tabellen von SPSS hässlich? Dann schau dir mal an, wie man mit wenigen Klicks die Tabellen in SPSS im APA-Standard ausgeben lassen kann.
7 Videotutorials
https://www.youtube.com/watch?v=M_6xwqyqhWg/https://www.youtube.com/watch?v=cn1DCh37wwQ/
https://www.youtube.com/watch?v=zYDj9MoIJuw/
8 Literatur
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences. Hillsdale, N.J: L. Erlbaum Associates
- Cohen, J. (1992). A power primer. Psychological bulletin, 112(1), 155.
- Rosenstein, L. D. (2019). Research design and analysis: A primer for the non-statistician.
Weitere nützliche Tutorials findest du auf meinem YouTube-Kanal.