

1 Die zweifaktorielle ANOVA
1.1 Ziel der zweifaktoriellen ANOVA
Die zweifaktorielle ANOVA (Varianzanalyse) testet den Einfluss zweier Faktoren auf eine Testvariable. Die zwei Faktoren können separat oder auch gemeinsam (= „Interaktion“) einen Einfluss auf die Testvariable entfalten. In SPSS ist die zweifaktorielle ANOVA mittels weniger Klicks durchführbar, wenn die entsprechenden Voraussetzungen geprüft worden.
1.2 Fiktives Beispiel
In einer Studie soll Pflanzenwachstum in Abhängigkeit von Rahmenbedingungen untersucht werden. Die erste Rahmenbedingung (= Faktor 1) ist die Umgebungstemperatur. Es existieren drei Arten von Gewächshäusern (= Faktorstufen), die unterschiedliche Temperaturen haben. Ein gänzlich unbeheiztes Gewächshaus (sehr kalt), ein minimal beheiztes Gewächshaus (kalt) und ein normal beheiztes Gewächshaus (normal). Innerhalb der Gewächshäuser gibt es eine zweite Rahmenbedingung (Faktor 2), welche der Einsatz von Dünger (ja oder nein) ist.Insgesamt gibt es folglich zwei Faktoren, einer ist dreistufig (Temperatur) der andere ist zweistufig (Dünger ja-nein).
- Pauschal wird bei einer weniger kalten Umgebungstemperatur ein höheres Wachstum erwartet (Haupteffekt für Temperatur).
- Zusätzlich wird durch den Einsatz von Dünger ein höheres Wachstum erwartet (Haupteffekt für Dünger).
- Schließlich wird erwartet, dass die beiden Faktoren in Kombination zu einem höheren Wachstum führen (Interaktionseffekt).
2 Voraussetzungen für die zweifaktorielle Varianzanalyse (ANOVA)
Die wichtigsten Voraussetzungen sind:
- zwei voneinander unabhängige Faktoren/Gruppen – mehr sind generell möglich, das Vorgehen analog
- metrisch skalierte y-Variable
- nominal/ordinal skalierte unabhängige Variablen (Faktoren)
- normalverteilte Fehlerterme innerhalb der Gruppen (= Faktorkombination), bzw. Residuen des Gesamtmodells
- Homogene (nahezu gleiche) Varianzen der y-Variablen innerhalb der Faktoren – sofern die Anzahl der Beobachtungen über die Faktoren unterschiedlich ist
3 Zweifaktorielle ANOVA in SPSS berechnen
Über das Menü in SPSS:
Analysieren > Allgemeines lineares Modell > Univariat
1. Als Faktoren sind die gruppentrennenden Merkmale/Variablen auszuwählen. Im Beispiel habe ich Temperatur und Düngereinsatz als Faktoren und versuche das Wachstum zu erklären.

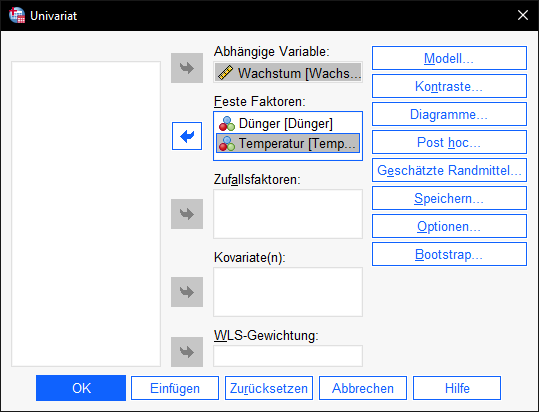
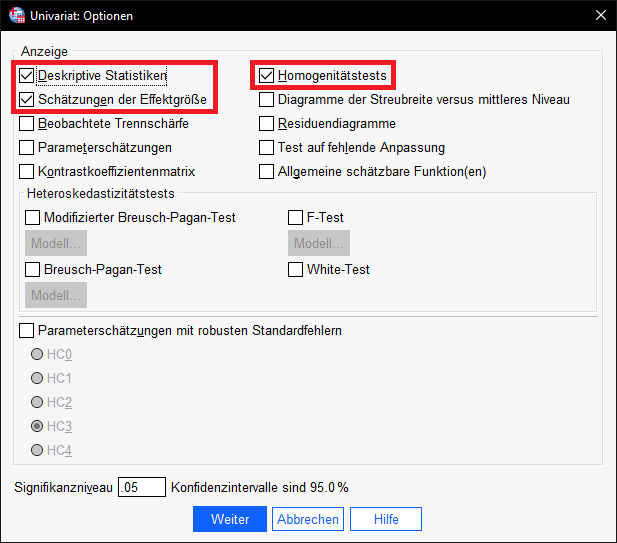
2. Unter dem Button „Optionen“ sind Deskriptive Statistiken, Homogenitätstests und Schätzungen der Effektgröße auszuwählen:

3. Unter dem Button „Geschätzte Randmittel“ werden die Haupteffekte sowie ein Interaktionsterm aus den beiden Faktoren in den Bereich „Mittelwerte anzeigen für“ eingefügt und die Haken bei „Haupteffekte vergleichen“ und „Einfache Haupteffekte vergleichen“ angehakt. Schließlich wird bei „Anpassung des Konfidenzintervalls“ noch Bonferroni ausgewählt, um vor Fehler 1. Art bei multiplem Testen auf dieselbe Stichprobe geschützt zu sein.
4. Bei Diagramme die Faktoren als „Horizontale Achse“ und „Separate Linien“ definieren und auf Hinzufügen klicken. Die Fehlerbalken sind optional, aber empfehlenswert.


4 Zweifaktorielle ANOVA – SPSS-Ergebnisse interpretieren
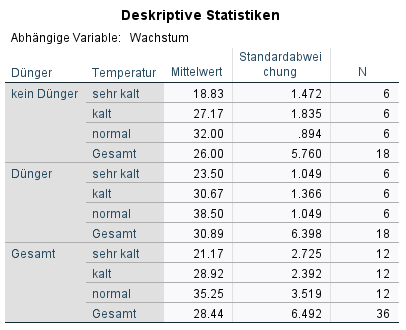
0. Ein deskriptiver Überblick ist ein guter Start und hilft bei der späteren Interpretation. Hier ist erkennbar, dass zunächst der erste Faktor (kein Dünger/Dünger) und dann unterteilt danach 3 Temperaturstufen (sehr kalt/kalt/Normal) aufgelistet werden. Erwartungsgemäß ist die Pflanzengruppe, die gedüngt und unter normalen Temperaturen wachsen konnte, am stärksten gewachsen. Weitere Schlüsse lassen sich erst in detaillierten Auswertungen vornehmen.

Ganz unten im Output findet man zusätzlich das Profildiagramm, dass dies noch mal grafisch veranschaulicht:


1. a) Die Voraussetzung der Varianzhomogenität ist nur zu prüfen, wenn die die Gruppen infolge der beiden Faktoren unterschiedlich groß sind. Im Beispiel ist erkennbar, dass für jede Kombination der beiden Faktoren n = 6 Beobachtungen vorliegen. Eine sorgfältige Versuchsplanung ist folglich wünschenswert und spart das Prüfen der Voraussetzung der Varianzhomogenität gänzlich (vgl. Field (2018), S. 259). Die Gruppengrößen müssen im Übrigen NICHT exakt sondern nur in etwa gleich sein.
b) Sollten die Gruppengrößen unterschiedlich sein, reicht ein Augentest der Varianzen aus. Hier sind Abweichungen von +/-20% noch im Rahmen, da die ANOVA recht robust bei leichten bzw. vereinzelten Varianzunterschieden ist (vgl. Blanca Mena et al. (2017)).
c) Der Levene’s-Test wird bei der Berechnung mit ausgegeben und findet sich immer noch größter Beliebtheit, weil er Scheinsicherheit gibt. Zunächst: Die Nullhypothese lautet, dass die Varianzen homogen sind. Die Signifikanz sollte demzufolge über 0,05 liegen, damit sie nicht verworfen werden kann und den Stichproben homogene Varianzen bescheinigt werden. Im Beispiel ist für die robuste Variante (zu empfehlen, vgl. Schultz (1985)) auf Basis des Medians p = 0,373 und die Nullhypothese von Varianzhomogenität kann demzufolge nicht verworfen werden. Es liegen also in etwa gleiche Varianzen vor.

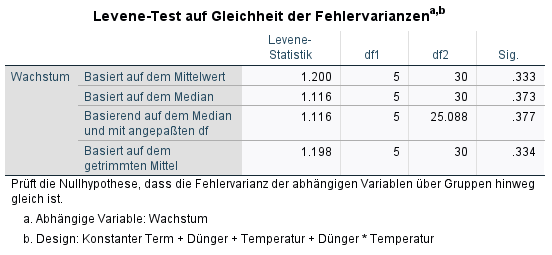
d) ACHTUNG: bei kleinen Stichproben ist der Levene’s Test zu liberal und bei großen Stichproben zu konservativ bzgl. Abweichungen von Varianzgleichheit (vgl. Field (2018), S. 259). Es sollte also auf die Rechnung und Angabe von Levene’s Test verzichtet werden.
Zum Levene’s Test: Field (2018), S. 259: “People have stopped using this approach for two reasons. First, violating this assumption matters only if you have unequal group sizes; if group sizes are equal this assumption is pretty much irrelevant and can be ignored. Second, tests of homogeneity of variance work best when you have equal group sizes and large samples (when it doesn’t matter if you have violated the assumption) and are less effective with unequal group sizes and smaller samples – which is exactly when the assumption matters. […] The take-home point is that you might as well always apply the correctuin and forget about the assumption.” (vgl. ausführlich: Zimmermann (2004))
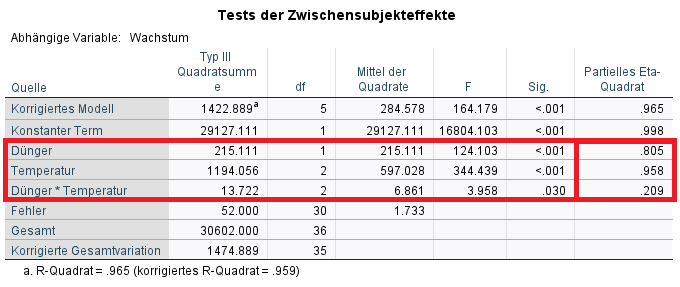
2. a) Die Tabelle „Tests der Zwischensubjekteffekte“ zeigt, ob die Faktoren an sich einen Einfluss auf die Testvariable, also das Pflanzenwachstum haben. Das wird zumeist auch als Haupteffekt bezeichnet. Das erkennt man in der Zeile, in der die vorher definierten Faktoren stehen, also Dünger und Temperatur. Ist die Signifikanz entsprechend kleiner als 0,05, geht man i.d.R. von statistischen Unterschieden aufgrund des jeweiligen Faktors hinsichtlich der Mittelwerte aus.
Hinweis: Eine harte Alphagrenze von 0.05 wird nicht empfohlen. Vielmehr werden p-Werte mit „Augenmaß“ sowie im Kontext und Lichte vorheriger Evidenz beurteilt (vgl. Wasserstein (2016)).

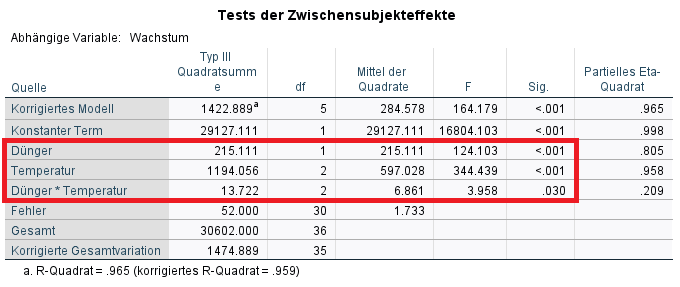
b) Ist der Interaktionseffekt (Faktor1*Faktor2) jedoch signifikant, hängt ein Teil des Effektes des einen vom anderen Faktor ab. Dies ist im Vorfeld des Testes entsprechend zu begründen. Ist der p-Wert des Interaktionseffekts hinreichend klein, werden die Haupteffekte allerdings NICHT interpretiert. Es wurde ja gerade festgestellt, dass sich die beiden Effekte bedingen und folglich nicht unter der jeweiligen Konstanthaltung des anderen Effektes interpretiert werden können. Ist der Interaktionseffekt nicht signifikant, werden entsprechend die Haupteffekte interpretiert.
c) Im Beispiel zeigt der Interaktionseffekt aus Dünger*Temperatur einen hinreichend kleinen p-Wert (p = 0,03). Somit ist eine Interpretation der Haupteffekte (nur Dünger und nur Temperatur) unnötig, da gerade deren Zusammenspiel das Pflanzenwachstum beeinflusst. Oder anders gesprochen, der eine Faktor verstärkt im Beispiel die Wirkung des anderen Faktors – dies sollte im Vorfeld ebenfalls klar sein.
Reporting: Der Interaktionseffekt zeigt einen hinreichend kleinen p-Wert: F (2, 30) = 3.958, p = 0.03; Demnach verstärken sich die beiden Faktoren Temperatur und Dünger hinsichtlich des mittleren Pflanzenwachstums.
Sollte kein Interaktionseffekt beobachtbar sein: Der Interaktionseffekt zeigt keinen hinreichend kleinen p-Wert: F (df1, df2) = F-Wert, p = p-Wert. Allerdings zeigt sich der Effekt für Dünger F (1, 30) = 124.103, p < .001 sowie der Effekt für Temperatur F (2, 30) = 344.439, p < .001.
Das Berichten der Effektstärke, siehe Abschnitt 6.1, ist zusätzlich empfehlenswert. Das Reporting ist in Abschnitt 8 ausführlich dargestellt.
5 Follow-up bei der zweifaktoriellen ANOVA
Im Abschnitt Geschätzte Randmittel im SPSS-Output gibt es je nach Faktor Paarweise Vergleiche. Diese sind lediglich unabhängige t-Tests für die entsprechenden Kombinationen der Faktoren. Diese sind nur entsprechend zu interpretieren, wenn der p-Wert des jeweiligen Effektes hinreichend klein ist. Die angegeben p-Werte wurden nach der Bonferroni-Korrektur angepasst, um Alphafehlerkumulierung , also das fälschliche Ablehnen der Nullhypothese zu verhindern.
5.1 Szenario I: beobachtbare Interaktion
Ist die Interaktion, wie im Beispiel, beobachtbar, wird bis an den Teil des Outputs gescrollt, an dem Faktor1*Faktor2 steht. In meinem Fall Dünger*Temperatur. Hier findet sich die entsprechende Tabelle „Paarweise Vergleiche„:
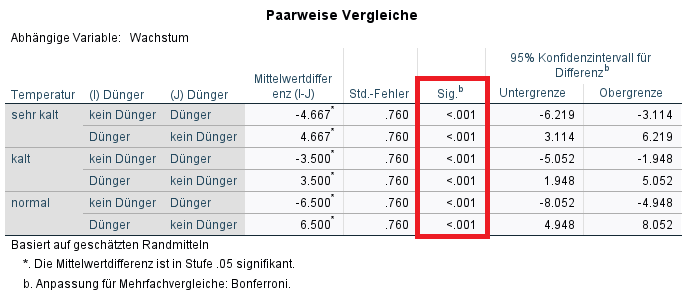
Hier findet sich in der ersten Spalte der erste Faktor (hier: Temperatur) mitsamt seinen Ausprägungen (sehr kalt, kalt und normal). Je Temperaturstufe gibt es dann einen Vergleich zwischen „Dünger“ und „kein Dünger“.
Konkret kann ich auf der Temperaturstufe sehr kalt einen Unterschied zwischen Dünger und kein Dünger beobachten, da der p-Wert mit p < .001 sehr klein ist. Ich kann auch die Mittelwertdifferenz ablesen. Der Mittelwert des Pflanzenwachstums der ersten Stufe (kein Dünger) wird reduziert um den Mittelwert des Pflanzenwachstums der zweiten Stufe (Dünger). Da gedüngte Pflanzen einen höheren Mittelwert des Pflanzenwachstums aufweisen (M = 23.5) als nicht gedüngte Pflanzen (M = 18.833), ist die Differenz negativ.
Analog kann ich Unterschiede auf den Temperaturstufen kalt als auch normal beobachten (jeweils p < .001) und schlussfolgern, dass, der Einsatz von Dünger den positiven Effekt von höherer Temperatur verstärkt.
Darüber hinaus gibt es im Output noch eine weitere Tabelle, die allerdings die „Reihenfolge“ der Faktoren vertauscht. In der ersten Spalte steht nun der andere Faktor (Dünger) und in der zweiten Spalte werden die Temperaturstufen paarweise verglichen. Es wird also deutlich, ob es Unterschiede hinsichtlich der Wirkung von Temperatur bei (k)einem Einsatz von Dünger gibt. Im Beispiel zeigen alle Vergleiche sehr kleine p-Werte.


Folglich kann ich schließen, dass eine höhere Temperatur bei gleichzeitigem Düngereinsatz zu einem stärkeren mittleren Pflanzenwachstum führt.
5.2 Szenario II: keine beobachtbare Interaktion
Hinweis: ich verwende dasselbe Datenbeispiel, dürfte aber Folgendes aufgrund eines beobachteten Interaktionseffektes nicht tun. Aus didaktischen Gründen zeige ich die Interpretation der “Haupteffekte” in diesem Artikel aber gleich mit. Die Reihenfolge der Tabellen kann unterschiedlich sein. Schaut im Ouput nach einer Tabelle, die nur die jeweiligen Faktorstufen vergleicht bzw. als Überschrift den Faktor hat. Sollten die Haupteffekte hinreichend kleine p-Werte aufweisen, werden die paarweisen Vergleiche für jene untersucht.
Ich beginne mit dem Haupteffekt für Dünger. Mathematisch werden vereinfacht betrachtet nur t-Tests zwischen den Stufen dieses Faktors gerechnet (unter Beachtung des Zustandekommens der Werte bei Beachtung des zweiten Faktors), in meinem Fall also nur ein t-Test für Dünger vs. kein Dünger.


Der p-Wert ist mit p
Der zweite Haupteffekt untersucht den Faktor Temperatur. Analog werden vereinfacht nur t-Tests für diesen Faktor und dessen Stufen gerechnet (unter Beachtung des Zustandekommens der Werte bei Beachtung des zweiten Faktors). In meinem Fall also sehr kalt vs. kalt, kalt vs. normal und sehr kalt vs. normal.

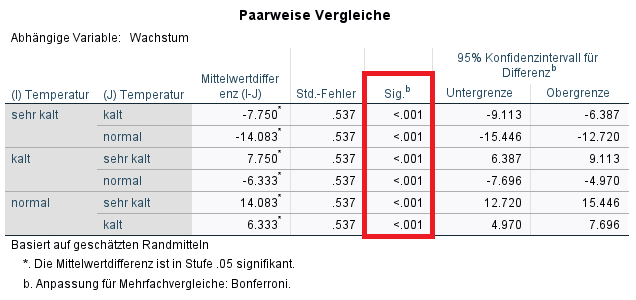
Der größte Unterschied ist bei sehr kalt vs. normal beobachtbar (14.083), was zeigt, dass die Pflanzen im Mittel bei einer normalen Temperatur und ohne Berücksichtigung der Zugabe von Dünger um 14.083 Einheiten stärker wachsen als bei einer sehr kalten Umgebungstemperatur. Die anderen paarweisen Vergleiche sind analog zu interpretieren.
6 Effektstärken
Bei den Effektstärken kann zwischen Effektstärken für die Haupteffekte und den Interaktionseffekt (Abschnitt 6.1) und Effektstärken für die paarweisen Vergleiche (Abschnitt 6.2 und 6.3) unterschieden werden.
6.1 Effektstärke für die jeweiligen Effekte – partielles Eta-Quadrat
Zunächst wird für jeden Effekt, sofern in Abschnitt 3 angefordert, die Effektstärke in Form des partiellen Eta-Quadrates in der letzten Spalte der Tabelle „Tests der Zwischensubjekteffekte“ mit ausgegeben. Dies geschieht stets unabhängig der Signifikanz und basiert auf den Quadratsummen.
Erneut der Hinweis: Wenn ein Interaktionseffekt beobachtbar ist, wird i.d.R. nur die Effektstärke für jenen berichtet, analog zur Argumentation in Abschnitt 4. Aus didaktischen Gründen zeige ich hier ausnahmsweise bei einem beobachtbaren Interaktionseffekt auch die Effektstärken für die Haupteffekte.
Das partielle Eta-Quadrat ist die nur durch diesen Faktor erklärte Varianz. Sie berechnet sich aus dem Quotienten der Quadratsumme des Faktors und der Summe aus der Quadratsumme des Faktors und der Quadratsumme des Fehlers:
![\[ {\hat\eta_{HE(Dünger)}^{2}} = \frac{215.111}{215.1111 + 52} = 0.8053. \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-d7df45972eed8237985b8cccdf7497ee_l3.png "Rendered by QuickLaTeX.com")

![\[ {\hat\eta_{HE(Temperatur)}^{2}} = \frac{1194.056}{1194.056 + 52} = 0.9582. \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-581d131b56bd7a7e371427a5b6f322c6_l3.png "Rendered by QuickLaTeX.com")

![\[ {\hat\eta_{HE(Interaktion)}^{2}} = \frac{13.722}{13.722 + 52} = 0.2088. \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-a08194b4d917957457d841f735e9d88b_l3.png "Rendered by QuickLaTeX.com")

Zur Einordnung der Effektstärken wird sich vorrangig ähnlicher Studien bedient. Sollten keine existieren, können forschungsfeldspezifische Grenzen herangezogen werden. Sollten auch diese nicht existieren, kann behelfsweise auf Cohen (1992), S. 157 zurückgegriffen werden.
Allerdings hat Cohen (1992) nur für die Effektstärke f entsprechende Grenzen angegeben, welche aber mit Cohen (1988), S. 284 in Eta² umgewandelt werden kann:
![\[ {f = \sqrt{ \frac{\eta^2}{1 + \eta^2} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-2aaecb14f16cfbf852c786ed72b4d4fd_l3.png "Rendered by QuickLaTeX.com")

Auf die detaillierte Umrechnung verzichte ich an dieser Stelle.
Cohen (1992), S. 157 nennt für f die Grenzen 0.1, 0.25 und 0.4 für kleine, mittlere und große Effekte.
In meinem Beispiel wäre der Interaktionseffekt nach Cohen (1992) unter der Grenze zum mittleren Effekt. Die Haupteffekte sind per se große Effekte nach Cohen (1992). Wegen des beobachtbaren Interaktionseffektes ist eine Einordnung aber hinfällig.
6.2 Effektstärken für paarweise Vergleiche
Hinweis: Die Berechnung über unabhängige t-Tests ist nur eine Approximation, weil bei den geschätzten Randmitteln nicht nur unabhängige t-Tests gerechnet werden, sondern dabei der jeweilige zweite Faktor mit beachtet wird. Beim t-Test wird allerdings genau dies ignoriert, weswegen Mittelwertdifferenzen mathematisch nicht identisch sind/sein können.
Szenario I: Beobachtbare Interaktion
Wenn eine Interaktion beobachtet werden konnte, werden für die paarweisen Vergleiche mit hinreichend kleinem p-Wert die Effektstärken berechnet. Das würde im Beispiel bedeuten, dass aus den in Abschnitt 5.1 beobachteten paarweisen Unterschieden die Effektstärken berechnet werden sollten. Im Beispiel sind es ungewöhnlich viele Vergleiche, was an der Konstruktion dieses fiktiven Beispiels liegt.
Zusammengefasst für mein Beispiel ist folgendes zu untersuchen:
“A) Unterschiede Faktor 1 (Temperatur)”
- Bei sehr kalter Temperatur gibt es beobachtbare Unterschiede zwischen kein Dünger und Dünger (p < 0.001).
- Bei kalter Temperatur gibt es beobachtbare Unterschiede zwischen kein Dünger und Dünger (p < 0.001).
- Bei normaler Temperatur gibt es beobachtbare Unterschiede zwischen kein Dünger und Dünger (p < 0.001).
Bei keinem Einsatz von Dünger gibt es:
- beobachtbare Unterschiede zwischen sehr kalter und kalter Temperatur (p < 0.001).
- beobachtbare Unterschiede zwischen sehr kalter und normaler Temperatur (p < 0.001).
- beobachtbare Unterschiede zwischen kalter und normaler Temperatur (p < 0.001).
- beobachtbare Unterschiede zwischen sehr kalter und kalter Temperatur (p < 0.001).
- beobachtbare Unterschiede zwischen sehr kalter und normaler Temperatur (p < 0.001).
- beobachtbare Unterschiede zwischen kalter und normaler Temperatur (p < 0.001).
Zu A) Unterschiede zwischen Stufen von Faktor 2 auf den verschiedenen Stufen von Faktor 1
Für die Unterschiede hinsichtlich des Einsatzes von Dünger wird je „signifikanter“ Temperaturstufe ein unabhängiger t-Tests gerechnet, also hier drei unabhängige t-Tests.
Zunächst sollte aber entweder ein Filter gesetzt werden, um nur einzelne Faktorstufen auszuwählen, oder eine geteilte Ausgabe von SPSS angefordert werden. Da ich in meinem Beispiel drei t-Tests benötige und nicht drei verschiedene Filter setzen möchte, lasse ich mir die Ausgabe entsprechend nach den drei Faktorstufen für Temperatur aufteilen.
Zum Aufteilen der Ausgabe gehe ich über Daten > Datei aufteilen.
Im nachstehenden Dialogfeld wähle ich „Ausgabe nach Gruppen aufteilen“ und schiebe meine Faktor Temperatur in das Feld „Gruppen basierend auf„:


Anschließend führe ich die unabhängigen t-Tests über Analysieren > Mittelwerte und Proportionen vergleichen > t-Test bei unabhängigen Stichproben durch

- Für die Faktorstufen, in denen es Unterscheide bzgl. des anderen Faktors gab, wird die Messvariable in das Feld Testvariable(n) gezogen und die Gruppierungsvariable definiert.
- Bei der Gruppierungsvariable müsst ihr definieren, welche Gruppen ihr vergleichen wollt, insbesondere, wenn ihr mehr als zwei habt, ist das besonders wichtig. Bei mir ist es nur kein Dünger (0) vs. Dünger (1)
- Schließlich sollte noch darauf geachtet werden, dass bei „Effektgrößen schätzen“ der Haken gesetzt ist.
Ich habe den daraus entstehenden Output etwas gekürzt und nur die jeweiligen Tabellen Effektgrößen bei unabhängigen Stichproben rauskopiert. Erinnerung: hier zu sehen sind Unterschiede Dünger vs. kein Dünger je Stufe des Faktors Temperatur.


Im Output sieht man dann in der Spalte Punktschätzung, bei Cohen’s d bzw. Hedges‘ Korrektur von d die entsprechenden Effektstärken. Effektstärken werden üblicherweise betragsmäßig, also stets positiv angegeben.
- Für eine sehr kalte Temperatur wäre der Unterschied zwischen kein Dünger vs. Dünger d = – 3.651 bzw. |d| = 3.651.
- Für eine kalte Temperatur wäre der Unterschied zwischen kein Dünger vs. Dünger d = – 2.164. bzw. |d| = 2.164.
- Für eine normale Temperatur wäre der Unterschied zwischen kein Dünger vs. Dünger d = – 6.669. bzw. |d| = 6.669.
- Darüber hinaus ist zu erwähnen, dass in manchen Disziplinen neben Cohen’s d auch Hedges‘ Korrektur von d oder Glass‘ Delta angegeben werden. Das ist individuell zu prüfen, wird aber von Grissom, Kim (2012), S. 69 empfohlen.
- Hinweis: Die Effektstärken sind z.T. riesig, was aber auf das konstruierte Datenbeispiel zurückzuführen ist.
- Berechnete Effektstärken für paarweise Vergleichen werden mit Effektstärken paarweiser Vergleiche ähnlicher Studien verglichen. Alternativ können fachspezifische Grenzen verwendet werden. Behelfsweise kann, wie in Abschnitt 6.1 auf die Grenzen von Cohen (1992) zurückgegriffen werden. Diese sind 0,2; 0,5 und 0,8 für kleine, mittlere und große Effekte.
Zu B) Unterschiede zwischen Stufen von Faktor 1 auf den verschiedenen Stufen von Faktor 2
Für die Unterschiede hinsichtlich der Temperaturstufen unter Beachtung des Einsatzes von Dünger oder nicht wird je „signifikanter“ Düngerstufe ein unabhängiger t-Tests gerechnet, also hier drei unabhängige t-Tests je Faktorstufe des Düngers (3 x 2 = 6 t-Tests).
Zunächst sollte aber entweder ein Filter gesetzt werden, um nur einzelne Faktorstufen auszuwählen, oder eine geteilte Ausgabe von SPSS angefordert werden. Da ich in meinem Beispiel drei t-Tests je Faktorstufe Dünger benötige und nicht drei x zwei verschiedene Filter setzen möchte, lasse ich mir die Ausgabe entsprechend nach den zwei Faktorstufen für Dünger aufteilen.
Zum Aufteilen der Ausgabe gehe ich über Daten > Datei aufteilen.
Im nachstehenden Dialogfeld wähle ich „Ausgabe nach Gruppen aufteilen“ und schiebe meine Faktor Düngerin das Feld „Gruppen basierend auf„:

Anschließend führe ich die unabhängigen t-Tests über Analysieren > Mittelwerte und Proportionen vergleichen > t-Test bei unabhängigen Stichproben durch.

Damit es nicht zu umfangreich wird, zeige ich hier lediglich die Ergebnisse für den Vergleich einer sehr kalten (0) mit einer kalten (1) Temperatur, jeweils auf der Faktorstufe Dünger sowie kein Dünger:


Im Output sieht man in der Spalte Punktschätzung, bei Cohen’s d bzw. Hedges‘ Korrektur von d die entsprechenden Effektstärken, die betragsmäßig, also stets positiv angegeben werden sollten.
- Für keinen Düngereinsatz hat der Unterschied zwischen sehr kalter und kalter Temperatur ein d = – 5.010 bzw. |d| = 5.010.
- Für einen Düngereinsatz hat der Unterschied zwischen sehr kalter und kalter Temperatur ein d = – 5.884 bzw. |d| = 5.884.
- Für keinen Düngereinsatz hat der Unterschied zwischen sehr kalter und normaler Temperatur ein d = – 10.811 bzw. |d| = 10.811.
- Für einen Düngereinsatz hat der Unterschied zwischen sehr kalter und normaler Temperatur ein d = – 14.302 bzw. |d| = 14.302.
- Für keinen Düngereinsatz hat der Unterschied zwischen kalter und normaler Temperatur ein d = – 3.349 bzw. |d| = 3.349.
- Für einen Düngereinsatz hat der Unterschied zwischen kalter und normaler Temperatur ein d = – 6.432 bzw. |d| = 6.432.
- Darüber hinaus ist zu erwähnen, dass in manchen Disziplinen neben Cohen’s d auch Hedges‘ Korrektur von d oder Glass‘ Delta angegeben werden. Das ist individuell zu prüfen, wird aber von Grissom, Kim (2012), S. 69 empfohlen.
- Hinweis: Die Effektstärken sind z.T. riesig, was aber auf das konstruierte Datenbeispiel zurückzuführen ist.
- Berechnete Effektstärken für paarweise Vergleichen werden mit Effektstärken paarweiser Vergleiche ähnlicher Studien verglichen. Alternativ können fachspezifische Grenzen verwendet werden. Behelfsweise kann, wie in Abschnitt 6.1 auf die Grenzen von Cohen (1992) zurückgegriffen werden. Diese sind 0,2; 0,5 und 0,8 für kleine, mittlere und große Effekte.
Szenario II: Keine Beobachtbare Interaktion
Erneut der Hinweis: ich verwende dasselbe Datenbeispiel, dürfte aber folgendes aufgrund eines beobachteten Interaktionseffektes nicht tun. Aus didaktischen Gründen zeige ich die Berechnung der Effektstärken für die Unterschiede für A) den Faktor 1 (Temperatur) und B) den Faktor 2 (Dünger) in diesem Artikel aber gleich mit.
Zu A) Faktor 1In Abschnitt 5.2 habe ich einen Unterschied beim Faktor Temperatur zwischen jeweils allen Faktorstufen beobachten können. Folglich muss ich für diese drei paarweisen Vergleiche jeweils auch die Effektstärken berechnen. Erinnerung: der Faktor Dünger spielt hier keine Rolle (er wird in Teil B dieses Abschnitts untersucht).
Es werden nun unabhängige t-Tests über Analysieren > Mittelwerte und Proportionen vergleichen > t-Test bei unabhängigen Stichproben durchgeführt. Die verschiedenen Faktorstufen bei der Gruppierungsvariable sind entsprechend zu definieren. In meinem Beispiel sind drei paarweise Vergleiche zu rechnen.
- Erneut ist beim Output nur die jeweils unterste Tabelle („Effektgrößen bei Stichproben mit paarigen Werten„) der drei t-Tests von Interesse.
- Der Übersicht wegen habe ich unnötige Tabellen entfernt, die entsprechenden Vergleiche sowie die Effektstärken markiert.

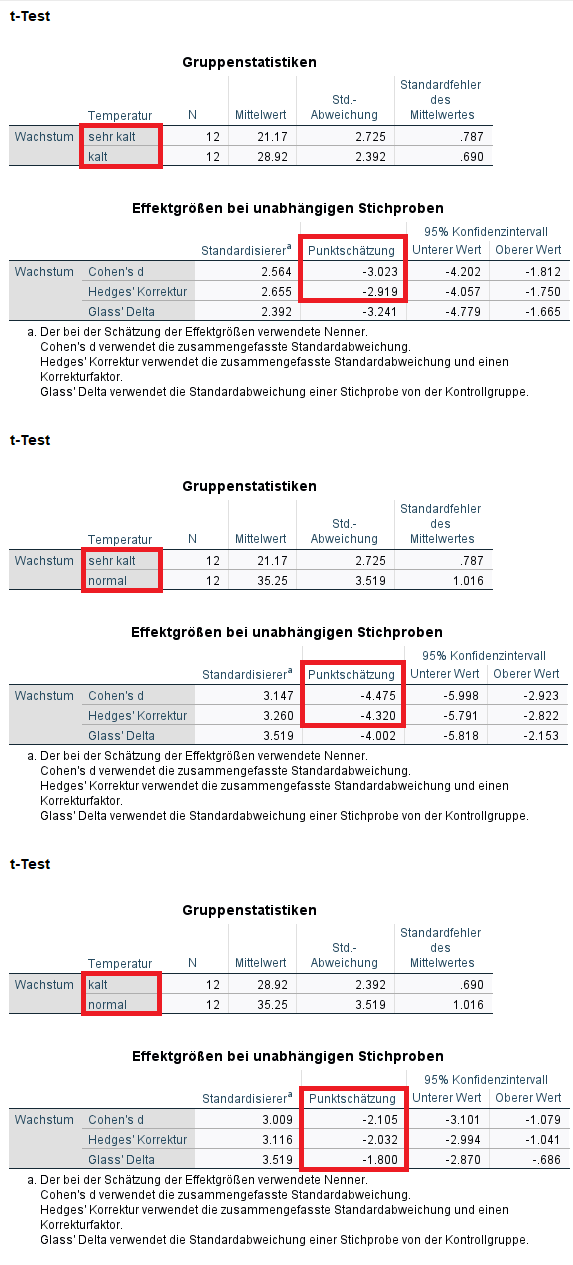
Berichtet wird erneut stets der Betrag, also die positive Effektstärke, die hier für den Unterschied zwischen sehr kalt und kalt, sehr kalt und normal sowie sehr kalt und kalt ermittelt wurde.
- Der Unterschied zwischen sehr kalter und kalter Temperatur ist d = -3.023 bzw. |d| = 3.023.
- Der Unterschied zwischen sehr kalter und normaler Temperatur ist d = -4.475 bzw. |d| = 4.475.
- Der Unterschied zwischen kalter und normaler Temperatur ist d = -2.105 bzw. |d| = 2.105.
- Sämtliche Unterschiede werden mit ähnlichen Studien, fachspezifischen Grenzen oder notfalls Cohen (1992) mit 0.2, 0.5 und 0.8 für kleine, mittlere und große Effekte eingeordnet.
- Im Beispiel sind es z.T. sehr große Unterschiede nach Cohen (1992) – das Beispiel ist konstruiert und reale Experimente haben zumeist deutlich kleinere Effekte.
Zu B) Faktor 2
In Abschnitt 5.2 habe ich einen Unterschied beim Faktor Dünger können. Folglich muss ich für diesen einen paarweisen Vergleich jeweils auch die Effektstärken berechnen. Erinnerung: der Faktor Temperatur spielt hier keine Rolle (er wird in Teil A dieses Abschnitts untersucht).
Es wird ein unabhängiger t-Test über Analysieren > Mittelwerte und Proportionen vergleichen > t-Test bei unabhängigen Stichproben durchgeführt. Die verschiedenen Faktorstufen bei der Gruppierungsvariable sind entsprechend zu definieren. In meinem Beispiel ist nur ein paarweiser Vergleich zu rechnen.
- Erneut ist beim Output nur die jeweils unterste Tabelle („Effektgrößen bei Stichproben mit paarigen Werten„) des t-Tests von Interesse.
- Der Übersicht wegen habe ich unnötige Tabellen entfernt, die entsprechenden Vergleiche sowie die Effektstärken markiert.


- Berichtet wird erneut stets der Betrag, also die positive Effektstärke, die hier für den Unterschied zwischen keinem Dünger und Dünger ermittelt wurde.
- Hier ist es d = – 0.803 bzw. |d| = 0.803.
- Sämtliche Unterschiede werden mit ähnlichen Studien, fachspezifischen Grenzen oder notfalls Cohen (1992) mit 0.2, 0.5 und 0.8 für kleine, mittlere und große Effekte eingeordnet.
- Im Beispiel ist es gerade so ein großer Unterschied nach Cohen (1992).
7 Zusammenfassung
Dieser Beitrag ist sehr umfangreich geworden, was aber den verschiedenen Szenarien und möglicherweise notwendigen follow-up-Untersuchungen geschuldet ist. Zusammenfassend ist festzuhalten:- Prüfen, ob ein Interaktionseffekt vorliegt.
- Wenn ja, werden nur für diesen paarweise Vergleiche mitsamt Effektstärken gerechnet und interpretiert – Szenario I in Abschnitt 5.2 und 6.2.
- Wenn nein, werden für beobachtbare Haupteffekte (Unterschiede in der abhängigen Variable über Faktorstufen) die p-Werte geprüft.
- Sollte einer oder beide Haupteffekte beobachtbar sein, bei gleichzeitiger Abwesenheit einer „signifikanten“ Interaktion, werden für jene entsprechend paarweise Vergleiche mitsamt Effektstärken gerechnet und interpretiert – Szenario II in Abschnitt 5.2 und 6.2.
8 Reporting
Beim Berichten wird sich auf das Wesentliche beschränkt.8.1 Szenario I: Beobachtbarer Interaktionseffekt
Beispielformulierung:Der Interaktionseffekt zeigt einen hinreichend kleinen p-Wert: F (2, 30) = 3.958, p = 0.030, partielles Eta² = 0.209. Demnach kann über die verschiedenen Temperaturstufen hinweg ein positiver Effekt des Düngereinsatzes beobachtet werden bzw. der Einsatz von Dünger verstärkt den positiven Effekt einer höheren Temperatur.
Die anschließenden paarweisen Vergleiche haben gezeigt, dass sich dies über alle Kombinationen von Faktorstufen hinweg zeigt. Kein Düngereinsatz zeigt bei sehr kalter Temperatur ein mittleres Wachstum von M = 18.83 (SD = 1.472), Düngereinsatz bei normaler Temperatur zeigt hingegen ein mittleres Wachstum von M = 30.89 (SD = 1.049).
Die Effektstärken der Unterschiede zwischen Düngereinsatz und keinem Düngereinsatz sind für jede Temperaturstufe als mindestens groß, z.T. sehr groß einzuschätzen (sehr kalt: p < .001, d = 3.651, kalt: p < .001, d = 2.164 sowie normal: p < .001, d = 6.669)
8.2 Szenario II: Kein Beobachtbarer Interaktionseffekt
Beispielformulierung mit Platzhaltern für Zahlen bei Berichten des Interaktionseffektes:Ein Interaktionseffekt konnte nicht beobachtet werden: F (df1, df2) = x.y, p = z;
Es konnte allerdings für den Faktor Temperatur ein Haupteffekt beobachtet werden: F (2, 30) = 344.439, p < .001, partielles Eta² = 0.958. Hier zeigten sich starke Unterschiede zwischen den Temperaturstufen (sehr kalt-kalt: p < .001 |d| = 3.023, sehr kalt-normal: p < .001 |d| = 4.475 sowie kalt-normal: p < .001 |d| = 2.105
Auch für den zweiten Faktor Dünger konnte ein Haupteffekt beobachtet werden: F (1, 30) = 124.103, p < .001, partielles Eta² = 0.805, welcher einen starken Unterschied zeigte bzw. d| = 0.803.
9 Downloads
Fiktiver Beispieldatensatz:Herleitung zur approximativen Berechnung von Cohen’s d:
10 Videotutorials
https://www.youtube.com/watch?v=l-MOl_LOVpw/
11 Literatur
- Blanca Mena, M. J., Alarcón Postigo, R., Arnau Gras, J., Bono Cabré, R., & Bendayan, R. (2017). Non-normal data: Is ANOVA still a valid option?. Psicothema, 2017, vol. 29, num. 4, p. 552-557.
- Cohen, J. (1988). Statistical Power Analysis for the behavioral sciences, 2nd Ed.
- Cohen, J. (1992). Quantitive Methods in Psychology: A power primer. Psychological Bulletin, S. 155-159.
- Field, A. (2018). Discovering Statistics Using IBM SPSS Statistics, SAGE.
- Grissom, R. J., Kim, J. J. (2012). Effect Sizes for Research, Routledge.
- Lantz, B. (2013). The large sample size fallacy. Scandinavian journal of caring sciences, 27(2), 487-492.
- Schultz, B. (1985). Levene’s Test for Relative Variation, Systematic Biology, Volume 34, Issue 4, December 1985, p. 449–456
- Wasserstein, R. L., Lazar, N. A. (2016). The ASA statement on p-values: context, process, and purpose. The American Statistician, 70(2), 129-133.
- Zimmerman, D. W. (2004). A note on preliminary tests of equality of variances. British Journal of Mathematical and Statistical Psychology, 57(1), 173-181.
Weitere nützliche Tutorials findest du auf meinem YouTube-Kanal.