

1 Warum Prüfung auf Normalverteilung?
Häufig hört man, dass für gewisse Verfahren die Daten normalverteilt sein müssen. Hier kann ich bereits mit dem ersten Mythos aufräumen. Eine pauschale Normalverteilung von Daten bzw. Variablen ist nicht notwendig. Es gibt jedoch Verfahren, die normalverteilte Residuen benötigen, so wie die lineare Regression. In manchen analytischen Tests, wie z.B. ANOVA-Verfahren, sollte die Testvariable je Zeitpunkt (ANOVA mit Messwiederholung) oder je Zeitpunkt pro Gruppe (Gemischte ANOVA) in etwa normalverteilt sein, was wiederum keine pauschale Normalverteilung der Variable an sich erfordert.
Eine Prüfung auf Normalverteilung von Variablen findet sich mitunter dennoch im Rahmen der deskriptiven Statistik oder weil Gutachter sich dies wünschen. Es gibt prinzipiell zwei Möglichkeiten der Prüfung auf Normalverteilung: analytisch (Abschnitt 3) und grafisch (Abschnitt 4), die ich in diesem Artikel vorstelle. Ich wähle fast ausschließlich die grafische Methode, was ich an den geeigneten Stellen auch begründet betonen werde.
2 Das Beispiel und Vorbemerkungen
Ich habe einen Datensatz mit 51 Beobachtungen in R eingelesen und möchte die Variable „Größe“ auf Normalverteilung testen. Der Dataframe heißt „df“. Da ich die Variablen nicht mit dem attach()-Befehl aus dem Dataframe herauslöse, adressiere ich sie stets mit „df$“, schreibe also „df$Größe“ im Verlauf des Artikels.
3 Analytische Prüfung
3.1 Kolmogorov-Smirnov-Test
Den Kolmogorov Smirnov-Test führe ich hier nur der Vollständigkeit wegen auf – er ist eigentlich nicht mehr zeitgemäß. Ihm fehlt (besonders) bei kleinen Stichproben die Teststärke (Aldor-Noiman et al. (2013)). Außerdem wird er, wie jeder analytische Tests bei zunehmender Stichprobengröße, fast automatisch signifikant (Field (2018)), obwohl eine Normalverteilung vorliegt. Kleine Abweichungen bei großen Stichproben stellen demnach ein Problem dar.
Die Nullhypothese des Kolmogorov-Smirnov-Tests beim Test auf Normalverteilung lautet: Die Daten sind normalverteilt.
Der Funktionsaufruf ist mit der ks.test()-Funktion relativ einfach. Die Testvariable wird eingesetzt (df$Größe). Lediglich das zusätzliche Argument „pnorm“ muss noch angefügt werden, damit tatsächlich auf Normalverteilung geprüft wird sowie Mittelwert und Standardabweichung der zu prüfenden Variable mit mean und sd.
ks.test(df$Größe, "pnorm", mean=mean(df$Größe), sd=sd(df$Größe))
Das führt zu folgendem Output:
Asymptotic one-sample Kolmogorov-Smirnov test
data: df$Größe
D = 0.078571, p-value = 0.9112
alternative hypothesis: two-sided
Warning message:
In ks.test.default(df$Größe, "pnorm", mean = mean(df$Größe),:
für den Komogorov-Smirnov-Test sollten keine Bindungen vorhanden sein
Hier geht schon der Ärger los, dass keine Bindungen vorhanden sein sollten. Bindungen sind mehrfach vorkommende Ausprägungen, konkret im Beispiel sind mehrere Menschen gleich groß – das ist nicht wirklich ungewöhnlich. Die Signifikanz (p = 0.9112) führt zum Beibehalten der Nullhypothese. Demzufolge würde man mit diesem Testergebnis eine Normalverteilung der Variable „Größe“ annehmen können.
3.2 Shapiro-Wilk-Test
Mit recht großer Power, auch bei kleinen Stichproben, kann der Shapiro-Wilk-Test (SW-Test) aufwarten. Allerdings leidet auch er unter dem „Phänomen“ des automatisch sinkenden p-Wertes bei steigender Stichprobengröße (gleiche Quellen) mit nur trivialen Abweichungen von der Normalverteilung. Dennoch, findet man ihn recht häufig.
Die Nullhypothese des Shapiro-Wilk-Tests beim Test auf Normalverteilung lautet: Die Daten sind normalverteilt.
In R wird hierfür die shapiro.test()-Funktion verwendet, in die lediglich die zu testende Variable eingefügt wird:
shapiro.test(df$Größe)
Das führt zu folgendem Output:
Shapiro-Wilk normality test
data: df$Größe
W = 0.97757, p-value = 0.4415
Der Output ist auch hier übersichtlich gehalten und nur der p-Wert von Interesse. p = 0,4415 liegt über den typischen Verwerfungsniveaus (hier: Alpha = 0,05). Demzufolge wird die Nullhypothese auch mit dem Shapiro-Wilk-Test beibehalten.
4 Grafische Prüfung
4.1 Q-Q-Plot / Q-Q-Diagramm
Das sog. Quantil-Quantil-Diagramm vergleicht die tatsächliche Verteilung mit der idealtypischen Normalverteilung – mit Hilfe der Quantile. Letzteres ist aber ehrlich gesagt unwichtig, da eigentlich nur ein Streudiagramm mit einer Gerade erzeugt und interpretiert werden muss, wie wir gleich sehen werden.
Für das Q-Q-Diagramm empfiehlt sich eine z-Standardisierung der betreffenden Variable mit dem scale()-Befehl. Ich erstelle im Dataframe df eine neue Variable „zGröße“:
df$zGröße
Anschließend reicht mir der Befehl qqnorm() für die Punkte der tatsächlichen Verteilung und qqline() für die "Normalverteilungsgerade":
qqnorm(df$zGröße)
qqline(df$zGröße)
Im Ergebnis erhalte ich ein Diagramm der folgenden Art:
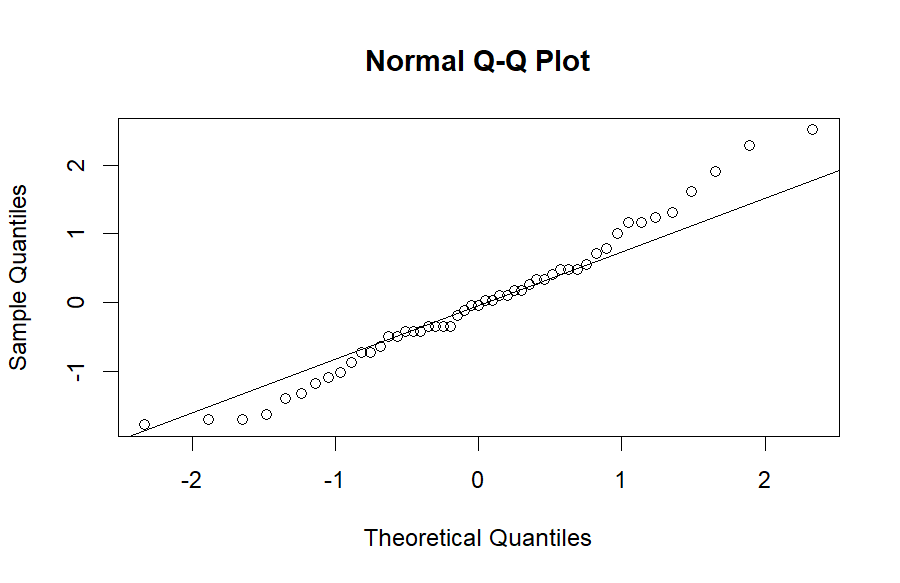

Hier ist es wichtig, dass die Beobachtungen (=Punkte) möglichst auf oder nahe der idealen Normalverteilung (= Gerade) liegen. Je weiter weg Punkte sind, desto eher sind sie "Ausreißer" bzw. von dem Punkt einer idealen Normalverteilung weg. Hier gibt es keine exakte Vorgehensweise, was normalverteilt ist und was nicht. Wenn die Mehrzahl der Punkte auf oder nahe der Gerade liegen, ist dies meist ausreichend, um von einer hinreichenden Normalverteilung auszugehen. Exakt einer Normalverteilung wird sowieso fast nie eine Verteilung entsprechen, weswegen der Anwender hier auch mitunter etwas pragmatischer sein kann. Es geht meist um in etwa und nicht exakt normalverteilte Daten.
4.2 Histogramm
In einem Histogramm werden die Ausprägungen gezählt und in Klassen in einem Säulendiagramm abgetragen. Im Zentrum der Verteilung sollten die Säulen höher sein und nach außen hin sollten sie (halbwegs) symmetrisch kleiner werden. Das sieht dann im Endeffekt wie eine stilisierte Glockenkurve aus und ist das, was wir am ehesten mit einer Normalverteilung verbinden. Der Code hierzu ist mit dem hist()-Befehl denkbar simpel:
hist(df$zGröße)
Ich habe hier aus Konsistenzgründen erneut die z-standardisierte Variable verwendet. Man kann es auch mit der unstandardisierten Variable darstellen, im Ergebnis ist der Aussagegehalt der gleiche, die Säulenhöhen sind aufgrund der anderen Klassenbreiten aber nicht die gleichen:
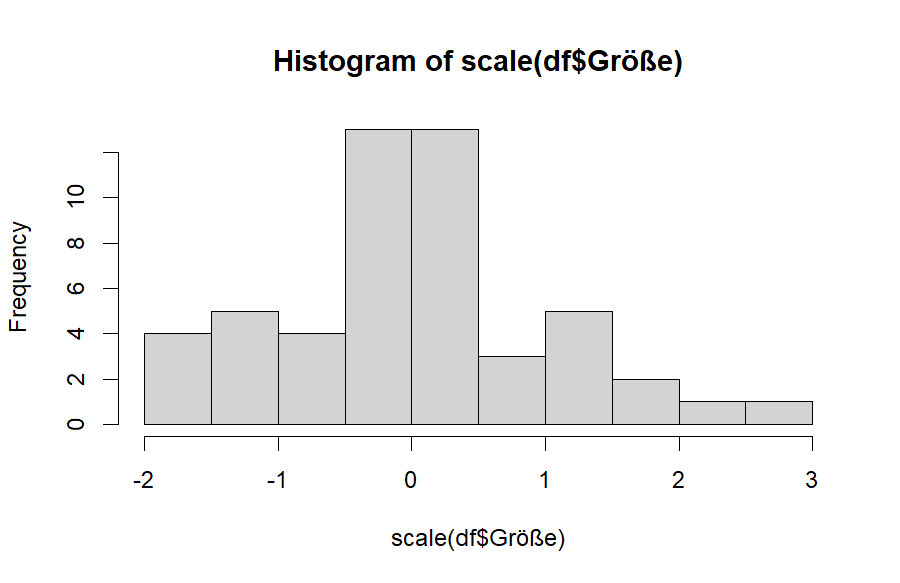
Wie bereits erwähnt, die Säulen sollten einer Glocke ähnlich sehen - in der Mitte hoch, nach außen hin jeweils niedriger werdende Säulen. Zwischen der 2 und 3 auf der x-Achse hat man langsam ausschleichende Häufigkeiten. Ein sog. long-tail. Auch hier würde man schließen, dass die Verteilung in etwa normalverteilt ist.
5 Literatur
- Sivan Aldor-Noiman, Lawrence D. Brown, Andreas Buja, Wolfgang Rolke & Robert A. Stine (2013) The Power to See: A New Graphical Test of Normality, The American Statistician, 67:4, 249-260, DOI: 10.1080/00031305.2013.847865
- Field, A. P. (2018). Discovering statistics using IBM SPSS statistics. London: SAGE Publications, S. 248f.