

1 Ziel der Moderation in R (Interaktion)
Eine Moderation (auch Interaktion) hat einen abschwächenden oder verstärkenden Einfluss einer zusätzlichen Variable M (= Moderator) auf eine Beziehung zwischen einer unabhängigen Variable (X) und einer abhängigen Variable (Y). Dieser Artikel zeigt, wie man eine Moderation in R modelliert und berechnet (Artikel zu SPSS).
2 Voraussetzungen der Moderation (Interaktion)
Die wichtigsten Voraussetzungen sind, analog zur multiplen linearen Regression:
- linearer Zusammenhang zwischen x-Variablen und y-Variable
- metrisch skalierte y-Variable (mitunter ist auch ordinal vertretbar – da gibt es große Diskussionen zu :-D)
- keine Multikollinearität – Korrelation der x-Variablen sollte nicht zu hoch sein
- normalverteilte Fehlerterme – Achtung beim analytischen Testen mit Kolmogorov-Smirnov und Shapiro-Wilk-Test
- Homoskedastizität – homogen streuende Varianzen des Fehlerterms
- keine Multikollinearität – übermäßige Korrelation der unabhängigen Variablen miteinander
- Kontrolle für einflussreiche Fälle bzw. “Ausreißer”
3 Das Prinzip der Moderation
Eine Moderation, auch Interaktion genannt, unterstellt einen moderierenden Einfluss einer Variable (M) auf einen Zusammenhang zwischen zwei Variablen (X->Y). Beispiel: der positive Einfluss der Intelligenz (X) auf den Abiturschnitt (Y) wird durch eine höhere Motivation (M) verstärkt. Konkret sieht das in folgender Abbildung so aus:
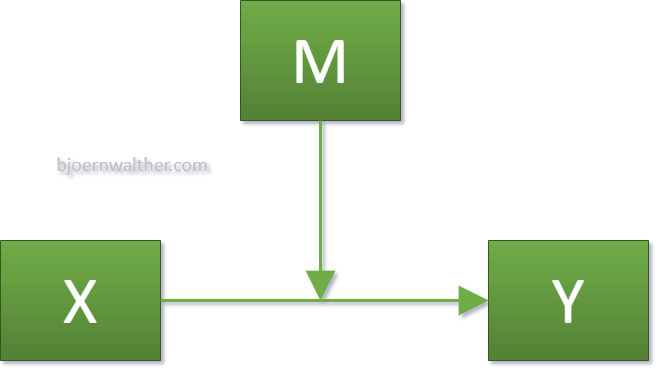

Mathematisch bzw. statistisch wird der Interaktionsterm mittels Multiplikation von unabhängiger Variable (X) und Moderator (M) gebildet (=X*M). Allerdings werden X und M weiterhin als unabhängige Variablen in das Modell aufgenommen. Dies zeigt die folgende Abbildung:

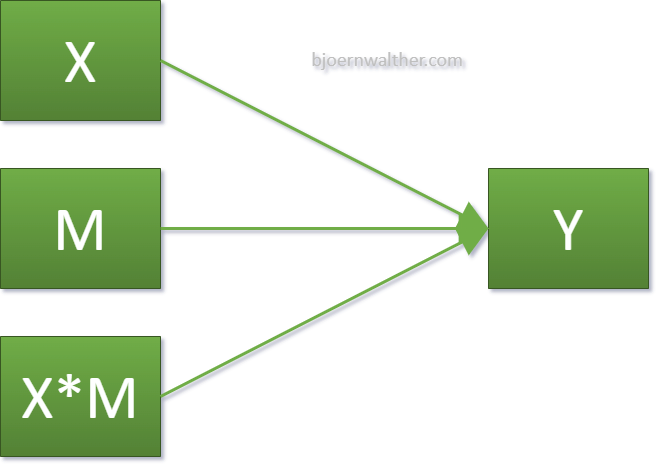
4 Durchführung der Moderation in R
Wie in obiger Abbildung ersichtlich, gehen in das Modell 3 unabhängige Variablen ein. X, M und X*M. In R werden mit Einführung eines Produktes automatisch dessen Faktoren aufgenommen. Man schreibt also letztlich nur den Interaktionsterm (plus eventuelle Kontrollvariablen) in das Modell, welches wie gewohnt bei einer linearen Regression in die lm()-Funktion kommt.
model
"[...] say that you are centering to render b1 and b2 interpretable and their hypothesis tests meaningful. But only say this if they otherwise would not be meaningful. And if you aren’t reporting b1 and b2 to the reader, then you aren’t even benefiting from this reason to mean-center. In that case, there really isn’t much point to centering at all."
5 Ergebnis der Moderation in R
Folgendes Ergebnis erhält man im Anschluss an die Durchführung der summary()-Funktion:
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1248.630 435.832 2.865 0.00833 **
IQ -3.003 3.918 -0.766 0.45062
Motivation -1143.432 217.241 -5.263 1.89e-05 ***
IQ:Motivation 12.093 1.949 6.205 1.72e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 74.64 on 25 degrees of freedom
Multiple R-squared: 0.9305, Adjusted R-squared: 0.9222
F-statistic: 111.7 on 3 and 25 DF, p-value: 1.319e-14
5.1 F-Test prüfen
Zunächst ist das Ergebnis des F-Tests zu prüfen. Die Nullhypothese, dass das aufgestellte Modell keinen signifikanten Erklärungsbeitrag leistet, kann bei typischerweise p<0,05 (bzw. eurem Alpha-Niveau) verworfen werden. Da der p-Wert mit 1,32e-14 (=0,0000000000000132) sehr sehr klein ist, wird die Nullhypothese hier verworfen. Folglich wird die Alternativhypothese angenommen, dass das aufgestellte Modell einen signifikanten Erklärungsbeitrag leistet. Hier kann also bedenkenlos fortgefahren werden.
F-statistic: 111.7 on 3 and 25 DF, p-value: 1.319e-14
ACHTUNG: Sollte p>0,05 bzw. größer eurem Alpha-Niveau sein, muss die Analyse abgebrochen werden.
5.2 Modellgüte - Bestimmtheitsmaß
Das Bestimmtheitsmaß R² gibt die Varianzaufklärung der abhängigen Variablen (Y), hier Abiturschnitt, durch das Modell in % an. Konkret werden 93,05% der Varianz der abhängigen Variable Abiturschnitt durch das Modell erklärt. Da es fiktive Daten sind, ist R² hier überdurchschnittlich groß.
Multiple R-squared: 0.9305, Adjusted R-squared: 0.9222
Das adjustierte Bestimmtheitsmaß korrigiert für eine Verzerrung zusätzlich aufgenommener unabhängiger Variablen. Es wird lediglich berichtet, aber nicht interpretiert.
5.3 Interaktionseffekt
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1248.630 435.832 2.865 0.00833 **
IQ -3.003 3.918 -0.766 0.45062
Motivation -1143.432 217.241 -5.263 1.89e-05 ***
IQ:Motivation 12.093 1.949 6.205 1.72e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Die Koeffiziententabelle ist wie folgt zu interpretieren:
- Der Interaktionseffekt (IQ:Motivation) besitzt einen p-Wert von 1,72e-06 (=0,00000172) und liegt damit unter allen gängigen Alpha-Niveaus.
- Ist der Interaktionseffekt signifikant, sollten die Effekte, aus denen er sich zusammensetzt (Motivation und IQ), nicht mehr einzeln interpretiert werden. Es wurde festgestellt, dass deren Zusammenwirken signifikant ist, weshalb das isolierte Wirken nicht mehr betrachtet werden sollte.
- Ist der Interaktionseffekt NICHT signifikant, können die Effekte, aus denen er sich zusammensetzt, wie gewohnt interpretiert werden. Alternativ kann das Modell auch ohne Interaktionseffekt erneut gerechnet und wie gewohnt interpretiert werden. Dies ist im Vorgehen zu dokumentieren.
- Sämtliche Kontrollvariablen bzw. unabhängige Variablen, die nicht mit dem Interaktionseffekt in Verbindung stehen, werden ebenfalls wie gewohnt interpretiert.
- Die Interpretation des Interaktionseffektes kann durch eine grafische Veranschaulichung stark vereinfacht werden und ist zudem besser schriftlich darstellbar.
6 Grafische Darstellung der Interaktion zur einfachen Interpretation
6.1 Interaktionsdiagramm erstellen
Für die grafische Darstellung kann das Paket interactions verwendet werden. Dies wird mit install.packages("interactions") installiert und mit library(interactions) geladen.
install.packages("interactions")
library(interactions)
Im interactions-Paket kann nun die interact_plot()-Funktion verwendet werden. In sie wird der Name des gerechneten Modells (hier: model), die unabhängige Variable (pred) sowie der Moderator (modx) übergeben:
interact_plot(model=model, pred = IQ, modx = Motivation)
6.2 Interaktionsdiagramm interpretieren
Im Ergebnis erhält man nun folgendes Diagramm:
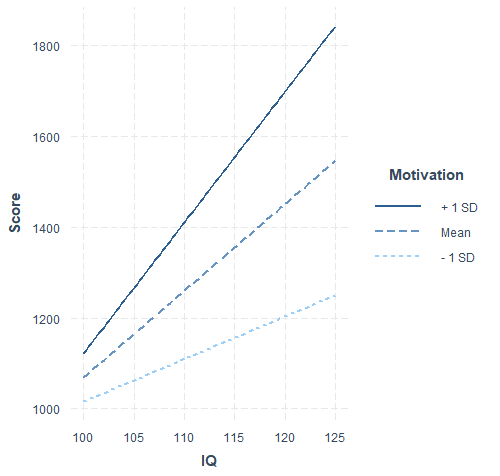
Die Interpretation ist nun wie folgt:
- Generell gilt, je höher der IQ (x-Achse), desto höher der Score (y-Achse).
- Die Motivation ist aufsteigend mit I) Mittelwert abzüglich Standardabweichung, II) Mittelwert und III) Mittelwert zuzüglich Standardabweichung in drei verschiedenen Geraden abgetragen. Siehe auch die Legende am rechten Rand des Diagramms.
- Die unterste Linie steht für die niedrige Motivation und hat eine moderate Steigung.
- Die oberste Linie steht für die hohe Motivation und hat eine starke Steigung.
- Mit zunehmender Motivation vergrößert sich demzufolge die Steigung der Geraden. Der Einfluss von IQ auf den Score nimmt also mit steigender Motivation zu.
- Anders formuliert: Eine höhere Motivation verstärkt den positiven Einfluss, den ein höherer IQ auf den Score hat.
7 Videotutorial
https://www.youtube.com/watch?v=zDREBIocB6U
8 Literatur
Hayes, Andrew F.(2018)., Introduction to Mediation Moderation and Conditional Process Analysis Second Edition : A Regression-Based Approach. New York; London: The Guilford Press.
9 Datensatz
Weitere nützliche Tutorials findest du auf meinem YouTube-Kanal.