

1 Ziel des Median-Split in R
Der Median-Split ist die Dichotomisierung einer Variable mithilfe des Medians. Die Ausgangsvariable kann metrisch oder ordinal sein und für zu einer dichotomen (binären) Zielvariable. Vereinfacht gesagt teilt man die Verteilung in der Mitte in eine “hohe” und eine “niedrige” Gruppe.
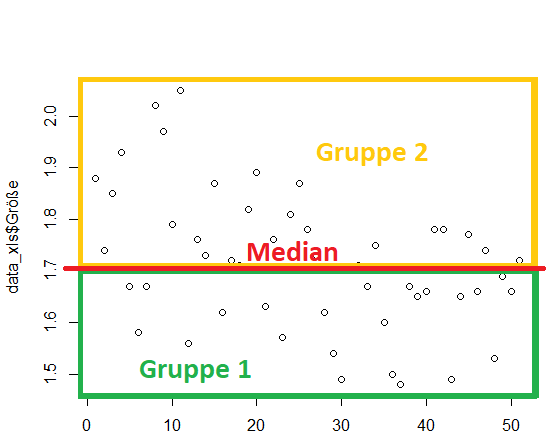

2 Anwendungsvoraussetzungen und Probleme beim Median-Split
Problematisch ist der Informationsverlust in den Variablen, das Sinken von Effektstärken und die höhere Chance “spurious effects” also nicht vorhandene Effekte zu “finden” (Field (2012): Discovering Statistics Using R, S. 361).
Der Median-Split ist zusätzlich schwierig rechtfertigbar. Deshalb ist eine theoretisch fundierte dichotome Modellierung im Vorfeld notwendig. Im Nachhinein zu dichotomisieren wird als p-Hacking angesehen und ist unwissenschaftlich.
Wenn nun ein Median-Split durchgeführt werden soll, gibt es 3 verschiedene Wege in R.
3 Median-Split in R durchführen
3.1 Mit den Bordmitteln von R
1. Man startet damit, den Median für die betreffende Variable (im Beispiel: Größe im Dataframe data_xls) zu errechnen. Hierzu nutzt man einfach die median()-Funktion und speichert diesen in einer separaten Variable, praktischerweise mit dem Namen “median”:
median <- median(data_xls$Größe)
2. Im zweiten Schritt erstellt man eine Kopie der Ausgangsvariable und benennt diese z.B. Gruppe. Diese Variable wird die dichotomisierte Variable werden. Ich nenne sie schlicht Gruppe und speichere sie im Dataframe "data_xls".
data_xls$Gruppe <- data_xls$Größe
3. Im dritten Schritt weist man dieser Variable die zwei Ausprägungen zu. In meinem Beispiel wird sie zu 1, wenn sie kleiner oder gleich dem Median ist und 2, wenn sie größer dem Median ist. Hier kann man beliebige Werte nehmen, ob 0 und 1 oder 1 und 2 macht für anschließende Berechnungen keinen Unterschied.
data_xls$Gruppe[data_xls$Gruppe <= median] <- 1
data_xls$Gruppe[data_xls$Gruppe > median] <- 2
Achtung: Bei Werten der Ausgangsvariable zwischen 0 und 1 sollte man von obiger Methode ablassen und lieber mit der ifelse()-Funktion arbeiten.
data_xls$Gruppe <- ifelse(data_xls$Gruppe <= median, 1, 2)
3.2 Mit dem car()-Paket und dessen recode()-Funktion
Nach der Installation des car()-Paketes (install.packages("car")) und dem Laden (library(car)) dessen, verwendet man die recode()-Funktion. Hier legt man für die erste Ausprägung den unteren und oberen Bereich (siehe unten) fest (in meinem Datensatz 0 bis einschließlich 1,71, geschrieben als "0:1.71") und weist ihm den Wert 1 zu. Für die zweite Ausprägung macht man das Gleiche. Die Gruppenvariable heißt hier "Gruppe2". Das Verwenden der oben gespeicherten Variable "median" funktioniert hier nicht.
install.packages("car")
library(car)
data_xls$Gruppe2 <- recode(data_xls$Größe, "0:1.71 = 1; 1.72:3 = 2")
Achtung: Man muss die Grenzen, also die Wertebereiche der Variable kennen. Mit min() und max() oder dem psych()-Paket und dem describe()-Befehl kann man sie sich bequem ausgeben lassen:
# Bordmittel
min(data_xls$Größe)
max(data_xls$Größe)
# psych-Paket
install.packages("psych")
library(psych)
describe(data_xls$Größe)
3.3 Mit dem sjmisc()-Pkaet und der dicho()-Funktion
Nach der Installation des sjmisc()-Paketes (install.packages("sjmisc")) und dem Laden (library(sjmisc)) dessen, verwendet man die dicho()-Funktion. Hier gibt man lediglich die zu dichotomisierende Variable an und weist sie einer neuen Variable zu (hier "Gruppe3" im Dataframe "data_xls"). Das Argument dich.by="median" ist hier entscheidend, da man auch andere Lagemaße verwenden kann. Standardmäßig wird bei kleiner oder gleich dem Median die Ausprägung auf 0 gesetzt und bei größer dem Median wird die Ausprägung auf 1 gesetzt.
install.packages("sjmisc")
library(sjmisc)
data_xls$Gruppe3 <- dicho(data_xls$Größe, dich.by ="median")
4 Videotutorial
https://www.youtube.com/watch?v=51IAqYF6w1E /
Weitere nützliche Tutorials findest du auf meinem YouTube-Kanal.