

1 Was ist Heteroskedastizität?
Heteroskedastizität ist im Kontext der einfachen linearen Regression oder multiplen linearen Regression eine zunehmende oder abnehmende Streuung der Residuen (mitunter auch Fehlerterme genannt). Die Residuen müssen allerdings homoskedastisch sein, also eine gleichmäßige lineare Streuung in allen Bereichen aufweisen.
2 Was hat Heteroskedastizität für Folgen?
Die Standardfehler der Regressionskoeffizienten werden bei vorhandener Heteroskedastizität (nach oben) verzerrt geschätzt. Sie sind damit nicht konsistent. Das führt wiederum dazu, dass die t-Werte nicht verlässlich geschätzt werden können. Schließlich führt das zu verzerrten p-Werten und damit zu einer Gefahr einer falschen Hypothesenentscheidung: insbesondere eine fälschliche Annahme der Nullhypothese (Fehler 2. Art) ist häufig die Folge. Achtung: die Koeffizienten selbst sind im Rahmen der Regression nicht verzerrt.
3 Analytisches Erkennen von Heteroskedastizität in SPSS
Wenn eine grafische Diagnose nicht ausreicht, kann man analytisch vorgehen. Zur analytischen Diagnose von Heteroskedastizität bewegt man sich in SPSS über “Analysieren” -> “Univariat“. Als abhängige Variable wird die abhängige Variable eingetragen. Die unabhängigen Variablen kommen in die Box “Kovariate(n)“.
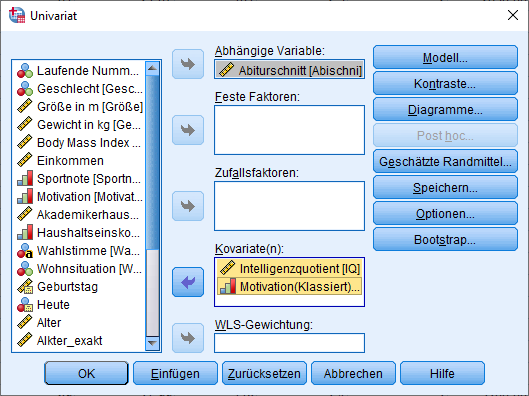

Als Nächstes geht ihr auf die Schaltfläche Optionen und erhaltet Folgendes:
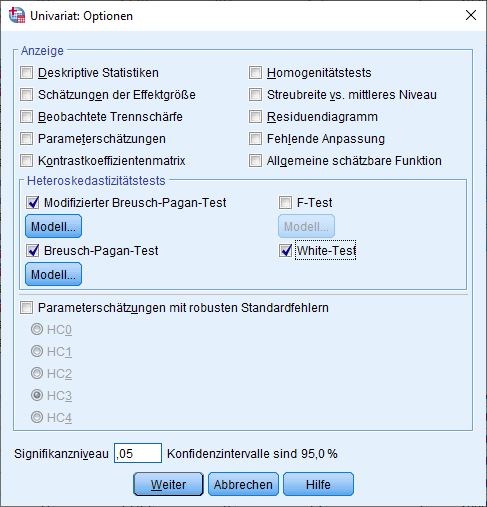

Hier können verschiedene Heteroskedastizitätstests ausgewählt werden:
- Breusch-Pagan-Test
- Modifizierter Breusch-Pagan-Test
- White-Test
Welcher ist nun zu wählen? Sind die Residuen normalverteilt, kann man den Breusch-Pagan-Test verwenden. Der modifizierte Breusch-Pagan-Test wird dann verwendet, wenn die Residuen zwar in etwa normalverteilt sind, die Kurtosis aber etwas abweicht, also manche Häufigkeiten der Residuen etwas zu hoch oder niedrig sind – verglichen mit der Normalverteilungskurve der Residuen. Der White-Test benötigt lediglich eine größere Stichprobe, da aufgrund von Kreuzprodukten sehr viele Freiheitsgrade “verbraucht” werden. Eine Folge dessen ist der Verlust an Teststärke, also Heteroskedastizität tatsächlich zu erkennen. Zudem kann er auch signifikant werden, wenn beispielsweise andere Verletzungen wie z.B. Endogenität (Korrelation von Residuen und abhängiger Variable) existieren (Wooldridge, J. M. (2009), S. 276).
Die Nullhypothese der Tests besagt, dass Homoskedastizität vorliegt. Idealerweise verwirft man also die Nullhypothese nicht. Eine Signifikanz von >0,05 ist demzufolge wünschenswert. Bei der Berechnung der Tests erhält man zum Beispiel folgendes Ergebnis:


Der Breusch-Pagan-Test zeigt hier einen Signifikanz von 0,147 und kann damit die Nullhypothese von Homoskedastizität nicht verwerfen. Es liegt also keine Heteroskedastizität, sondern Homoskedastizität vor.
4 Was tun bei Heteroskedastizität?
Es gibt verschiedene Wege Heteroskedastizität zu kontern. Es besteht die Möglichkeit, eine Weighted Least Squares-Regression zu rechnen. Allerdings ist das unnötig kompliziert, auch im Hinblick auf die Interpretation. Viel einfacher und direkt in SPSS implementiert ist die Verwendung von heteroskedastizitätskonsistenten bzw. heteroskedastizitätsrobusten Schätzern. Dies hat zur Folge, dass die Standardfehler nicht mehr verzerrt sind.
Diese Funktion ist allerdings nicht im Regressions-Dialogfeld implementiert. Dazu muss man erneut wie oben bereits gezeigt über “Analysieren” -> “Univariat” und auf die Schaltfläche Optionen gehen
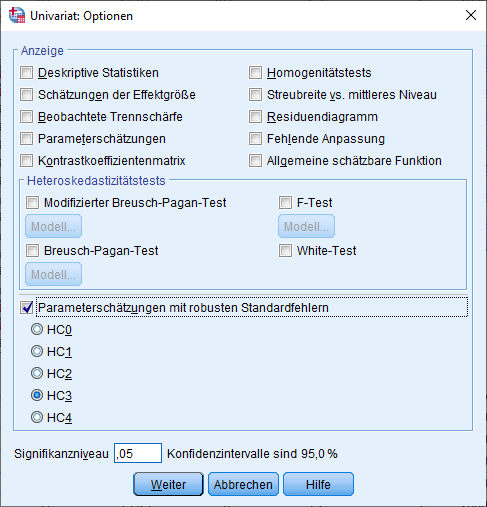
Euch interessiert an dieser Stelle lediglich “Parameterschätzungen mit robusten Standardfehlern“. Hier setzt ihr einen Haken und könnt nun zwischen HC0, HC1, HC2, HC3 und HC4 auswählen. Immer wieder kommt die Frage, welche HC der beste ist. Die Antwort ist nüchtern gesagt, das keinen besten gibt. Es existieren aber zwei sinnvolle Richtlinien von Hayes (2007), S. 713:
- Cribari-Neto (2005) simulation results also suggest the superiority of HC3 over its predecessors (HC0-HC2).
- Cribari-Neto’s (2004) simulations show that HC4 can outperform HC3 in terms of test size control when there are high leverage points and nonnormal errors.
Laut Hayes empfiehlt sich am ehesten die Nutzung HC3. HC4 ist häufig nur dann sinnvoll, wenn die Residuen nicht normalverteilt sind oder high leverage points existieren. Letzere sind Ausreißer, die – grafisch gesprochen – insbesondere in x-Richtung auftreten
Nach der Ausführung von HC3 bekommt man die Tabelle “Parameterschätzungen mit robusten Standardfehlern“, die man wie gewohnt zur Interpretation der Regression verwendet.
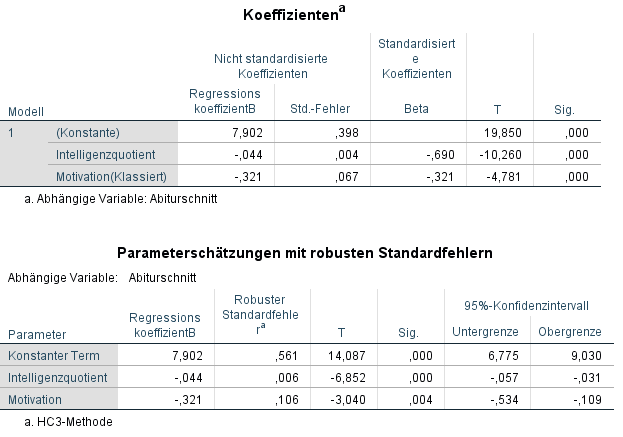

Oben sind zwei Tabellen direkt gegenübergestellt. Man sieht die normale Koeffizienten-Tabelle (oben) und die Parameterschätzungen mit robusten Standardfehlern (unten). Erkennbar sind die identischen Koeffizienten. Allerdings unterscheiden sich die Standardfehler dann doch recht deutlich. Zwar hat dies nur minimale Auswirkungen auf die Signifikanz, das ist in meinem konstruierten Beispiel allerdings nicht verwunderlich.
Hinweis: Es gibt inzwischen auch HC5, dieser ist allerdings noch nicht in SPSS implementiert. In früheren Versionen von SPSS (24 oder niedriger) ist keinerlei Schätzung von robusten Standardfehlern wie HC0-HC4 implementiert.
5 Literatur
- Hayes, A. F., & Cai, L. (2007): Using heteroskedasticity-consistent standard error estimators in OLS regression: An introduction and software implementation. Behavior research methods, 39(4), 709-722
- Wooldridge, J. M. (2009). Introductory econometrics: A modern approach. Mason, OH: South Western, Cengage Learning. Speziell S. 271-276.
6 Video mit Schnelltest
https://www.youtube.com/watch?v=mxiqCr9qjH4/