
Im Vorfeld jeder statistischen Untersuchung sollte mittels einer Poweranalyse sichergestellt werden, dass eine hinreichend große Menge an Probanden/Beobachtungen vorliegt. Warum? Kurz gesagt, damit der Test auch die Chance hat, einen Effekt erkennen zu können. Diese Chance nennt man auch statistische Power.

1 Vorbemerkungen
1.1 Statistische Power (Teststärke)
Teststärke (sog. statistische Power) beschreibt die Fähigkeit eines Tests, einen in der Stichprobe tatsächlich vorhandenen Effekt auch erkennen zu können und ist essenziell – nur leider ist das zu wenig bekannt. Beim Mann-Whitney-U-Test (auch kurz nur U-Test oder Wilcoxon-Mann-Whitney-Test) ist der Effekt offensichtlich ein Unterschied zwischen den Gruppen.
Die Power berechnet sich aus 1 abzüglich des Beta-Fehlers.
Der Beta-Fehler beschreibt das fälschliche Beibehalten der Nullhypothese. Hier kann man gut erkennen, dass Power und Beta-Fehler (auch Fehler 2. Art) direkt zusammenhängen:
Ich erhöhe die Power, wenn ich den Beta-Fehler minimiere. Hier sind 5% Fehlerwahrscheinlichkeit erstrebenswert, somit ist die Power 1 – 0,05 = 0,95 (95%). Mehr ist kaum praktikabel. Als Kompromiss findet man als Untergrenze 0,8 – also 80%. Eine geringere Power im Vorfeld anzunehmen, ist kaum rechtfertigbar. Auch 0,8 muss begründet sein.
1.2 Alpha-Fehler
Der Alpha-Fehler (auch Fehler 1. Art) ist das fälschliche Ablehnen der Nullhypothese. Typisch ist als Grenze für Alpha 5% (0,05). Man akzeptiert also eine maximale Alpha-Fehlerwahrscheinlichkeit von 5%. Weitere typische Grenzen sind 1%, 0,1% oder sogar 10%. Achtung, es kommt hier häufig auf den Kontext an. Niedriger kann pauschal als besser erachtet werden – es geht ja um die Fehlervermeidung.
1.3 Effektstärke
Im Vorfeld benötigt man die Effektstärke, also wie stark der beobachtete Effekt wohl sein wird bzw. vermutet wird. Im Kontext des Mann-Whitney-U-Tests verwendet man normalerweise das Effektstärkemaß r nach Cohen (1988)/Cohen (1992). Allerdings verwendet G-Power Cohen’s d. Diese Effektstärke ist aus dem t-Test für unabhängige Stichproben bekannt und wird analog berechnet.
Es gibt hierzu verschiedene Herangehensweisen zur Festlegung im Rahmen der Poweranalyse:
- Der einfachste Weg ist eine Orientierung an Vergleichsstudien und Verwendung der dort angegebenen Effektstärke. Sollte keine angegeben sein, kann man die mitunter nachträglich mit den angegebenen Populationsparametern ermitteln.
- Der praktische Weg ist das Festlegen auf Basis der Erfahrung des Forschers. Dies ist aber subjektiv und eine Begründung mit persönlicher Erfahrung kann bei Gutachtern schnell zu einer ablehnenden Haltung führen.
- Der pragmatische Weg ist die Annahme eines mittleren Effektes (d = 0.5). Auch hier ist eine Begründung notwendig und kann nicht einfach so getroffen werden – nicht selten findet man aber keine.
Die Konventionen nach Cohen sind folgende:
- d > 0,2 – kleiner Effekt
- d > 0,5 – mittlerer Effekt
- d > 0,8 – großer Effekt
1.4 Parent distribution
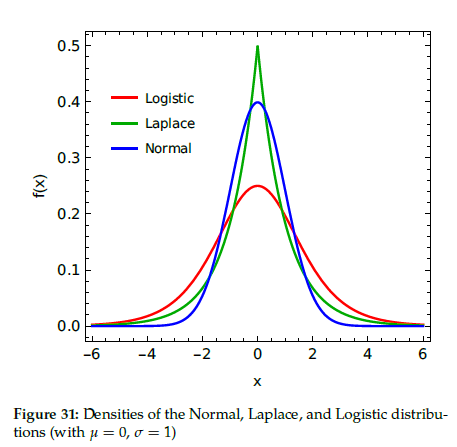
Im Manual zu GPower auf S. 56 findet man obige Abbildung, die aufzeigt, dass die Kurtosis der Verteilung den Unterschied macht. Ist man sich im Vorfeld unsicher, welche Verteilung zutreffend ist, ist die konservative Wahl „Normal“, also Normalverteilung.

1.5 Gerichtetheit der Hypothese
Typischerweise testet man ungerichtet, also zweiseitig. Man weiß also nicht, welche Gruppe einen höheren mittleren Wert der Testvariable aufweist (Gruppe A und B unterscheiden sich). Testet man einseitig, vermutet man im Vorfeld, dass Gruppe A einen höheren Wert der Testvariable hat als Gruppe B (oder umgekehrt).
2 Die Mindeststichprobengröße mit G*Power
Zunächst ist der richtige Test auszuwählen, was am einfachsten über das obere Menü funktioniert.
Means -> Two Independent Groups: Wilcoxon (non-parametric)
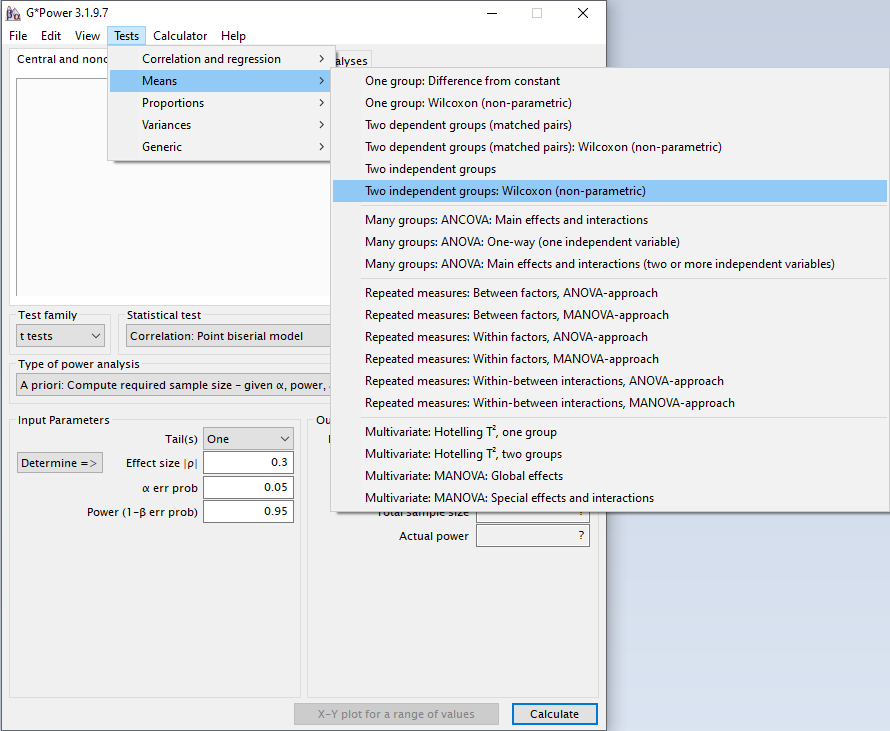

Bei Type of Power Analysis ist zwingend a priori auszuwählen.
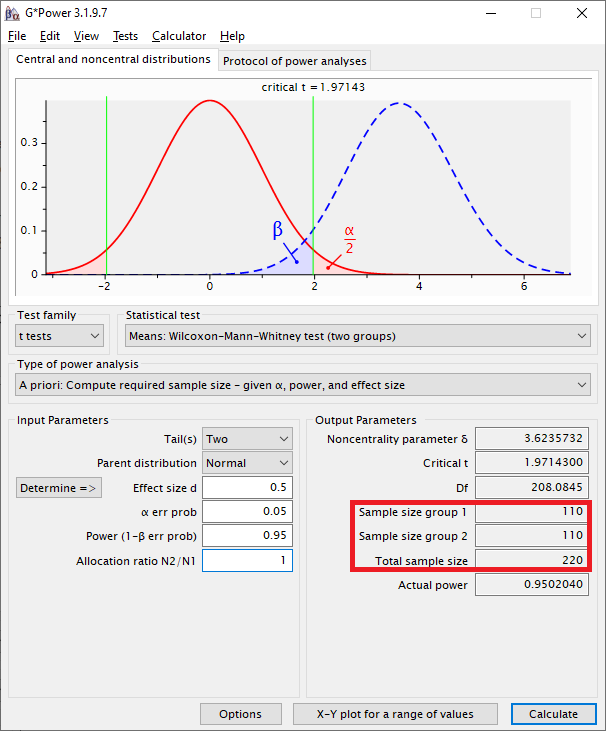
Entsprechend sind nun Gerichtetheit des Tests, Effektstärke (vermutetes Cohens d, siehe oben), Alphafehler (typisch 5%), statistische Power (typisch 95%) und Allocation Ratio einzutragen. Letzteres kann man mit 1 annehmen oder wenn man die Aufteilung der Grundgesamtheit kennt, kann man diese hier eintragen.
Bei einem zweiseitigen Test mit mittlerer Effektstärke von d = 0,5, einer konservativen Annahme der Verteilung als Normal, Alpha 5%, Power 95% und Allocation Ratio von 1 ergibt dies einen mindestens notwendigen Stichprobenumfang von n = 220 Beobachtungen. Je Gruppe also 110 Beobachtungen.

3 Powertabellen
3.1 Zweiseitiges Testen
Hier eine Übersicht für verschiedene Effektstärken bei unterschiedlichen Power-Niveaus bei zweiseitigem Test:
Mann-Whitney-U-Test/Wilcoxon-Mann-Whitney-Test (2-seitig)
Cohens d Alpha Power (1-Beta) n1 n2 N
0,8 0,05 0,95 44 44 88
0,5 0,05 0,95 110 110 220
0,2 0,05 0,95 682 682 1364
0,8 0,05 0,8 27 27 54
0,5 0,05 0,8 67 67 134
0,2 0,05 0,8 412 412 824
0,2 0,01 0,95 935 935 1870
Es ist recht deutlich erkennbar, dass mit sinkender Effektstärke bei gleichbleibender Power die notwendige Stichprobengröße (N) stark steigt. Der „worst case“ wäre eine kleine Effektstärke von 0,2 bei einem Alphafehler von 1% sowie einer Power von 95%. Hier wären insgesamt 1870 Beobachtungen notwendig.
3.2 Einseitiges Testen
Die Übersicht für verschiedene Effektstärken bei unterschiedlichen Power-Niveaus bei einseitigem Test:
Mann-Whitney-U-Test/Wilcoxon-Mann-Whitney-Test (1-seitig)
Cohens d Alpha Power (1-Beta) n1 n2 N
0,8 0,05 0,95 37 37 74
0,5 0,05 0,95 92 92 184
0,2 0,05 0,95 568 568 1136
0,8 0,05 0,8 21 21 42
0,5 0,05 0,8 53 53 106
0,2 0,05 0,8 325 325 650
0,2 0,01 0,95 828 828 1656
Man kann hier gut erkennen, dass man bei einseitigen Tests ein wenig an der Mindeststichprobengröße „sparen“ kann. Es hilft also im Vorfeld gerichtete Hypothesen aufzustellen.
4 Videotutorial
https://www.youtube.com/watch?v=IbePVTt8K4A
5 Literatur
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences. New York, NY: Psychology Press, Taylor & Francis Group
- Cohen, J. (1992). A power primer. Psychological bulletin, 112(1), 155-159.