

1 Ziel des Chi-Quadrat (Chi²)-Anpassungstests in SPSS
Der Chi²-Anpassungstest prüft eine kategoriale/nominale (wahlweise auch ordinale) Variable auf eine hypothetische Verteilung. Der einfachste Fall wäre die Gleichverteilung, also das jede Ausprägung in etwa gleich häufig vorkommt. Jedwede andere Verteilungsannahme kann auch geprüft werden.
2 Voraussetzungen des Chi²-Anpassungstests in SPSS
- Eine nominale skalierte Variable mit mindestens zwei Ausprägungen (ordinal funktioniert auch)
- Die Fälle sollten unabhängig voneinander sein.
- Eine vermutete Verteilung, auf die getestet werden soll
3 Durchführung des Chi²-Anpassungstests in SPSS – ein Beispiel
Die Nullhypothese beim Chi²-Anpassungstests geht stets von Gleichheit der beobachteten und erwarteten Häufigkeiten aus.
In meinem Datensatz möchte ich zunächst prüfen, ob die Wohnsituation meiner Probanden gleichverteilt ist. Also kommt jede der drei Ausprägungen (Wohnung, Reihenhaus, Einfamilienhaus) über die Probanden hinweg gleich oft vor? In meinem Beispiel müssten bei 51 Probanden demnach jede der drei Ausprägungen 17 Mal vorkommen.
3.1 “Klassische Dialogfelder”
Der Chi²-Anpassungstests ist zu finden unter Analysieren -> Nicht parametrische Tests -> Klassische Dialogfelder -> Chi-Quadrat.
Aus den im Datensatz vorhandenen Variablen (linkes Feld) ist die Testvariable herauszusuchen und in das rechte Feld (“Testvariablen”) aufzunehmen.
3.1.1 Unterstellte Gleichverteilung
Sollte man eine ungefähre Gleichverteilung erwarten, wird im Bereich “Erwartete Werte” die Markierung bei “Alle Kategorien gleich” belassen.


3.1.2 Unterstellte andere Verteilung
Erwartet man allerdings andere Häufigkeiten, kann man dies bei “Werte” eingeben. Die Werte werden hier entsprechend der Reihenfolge bei den Wertelabels eingegeben. Die Wohnung hat die Ausprägung 1 und würde als Erstes einen Wert eingetragen (z.B. 15) bekommen. Das Reihenhaus (Ausprägung 2) erwarte ich auch 15 Mal, das Einfamilienhaus (3) allerdings 21 Mal.
WICHTIG: Die Summe der erwarteten Anzahlen sollte der Beobachtungen entsprechen – in meinem Fall 51.

Unter “Optionen” kann man sich noch deskriptive Statistiken ausgeben lassen, also N, Mittelwert, Standardabweichung, Minimum und Maximum. Dies ist nicht zwingend notwendig, teilweise bei kategorialen Variablen sogar irreführend. Einen Mittelwert bei der Wohnsituation kann man kaum interpretieren, sodass diese Option nur bei ordinalen Testvariablen sinnvoll ist.
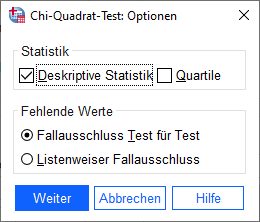

Erwartet man Häufigkeiten unter 5, sollte man zusätzlich beim Button “Exakt” die Option “Exakt” auswählen. Das sollte man deswegen wählen, da die in solchen Fällen asymptotisch ermittelte Signifikanz verzerrt ist.


3.2 Neue Dialogfelder
Der Chi²-Anpassungstests ist ebenso über die neuen Dialogfelder zu finden, unter Analysieren -> Nicht parametrische Tests -> Eine Stichprobe.
Als Nächstes ist im Reiter “Felder” die Testvariable einzufügen bzw. alle Variablen die nicht Testvariablen sind, aus diesem Feld zu entfernen.


Im nächsten Schritt geht es in den Reiter “Einstellungen”
Hier geht es darum, den richtigen Test auszuwählen. Zwar funktioniert auch die automatische Auswahl recht gut, aber man sollte hier schon den gewünschten Test direkt auswählen, speziell, wenn nicht auf Gleichverteilung geprüft wird.

Erneut besteht hier die Möglichkeit unter Optionen die erwarteten Häufigkeiten einzugeben, sofern man nicht von einer Gleichverteilung ausgeht. Auch hier gilt, die Summe der Häufigkeiten sollte der Anzahl der Beobachtungen entsprechen – hier 51. Die Bezeichnung “Relative Häufigkeit” ist hier etwas unglücklich gewählt, da dies Prozentwerte suggeriert. Es sind aber absolute Häufigkeiten der jeweiligen Merkmalsausprägung gemeint. Analog zu oben müssen die Wertelabels der Ausprägungen hier beachtet werden.


Geht man von einer Gleichverteilung aus, muss offensichtlich nichts geändert werden.

Zu guter Letzt noch der Hinweis, dass bei erwarteten Häufigkeiten unter 5 an dieser Stelle kein exakter Test, auch nicht unter Testoptionen, angefordert werden kann und dies nur über die “klassischen Dialogfelder” (siehe oben) möglich ist.
4 Interpretation der Ergebnisse des Chi²-Anpassungstests in SPSS
4.1 Output der “Klassischen Dialogfelder”
Nach Klick auf OK erhält man eine kleine Übersicht an Ergebnistabellen. Die Tabelle Häufigkeiten zeigt die beobachteten und erwarteten Häufigkeiten sowie die Residuen. Die Residuen sind die Abweichungen der erwarteten von den beobachteten Häufigkeiten. Je geringer die Residuen, desto geringer sind die Abweichungen und desto wahrscheinlicher ist das Beibehalten der Nullhypothese.


Wir können in meinem Fall sehen, dass durchaus Unterschiede bestehen, also die Residuen verschieden von Null sind. Wichtiger ist nun aber die Tabelle “Teststatistiken“.
Hier stehen die Chi-Quadrat-Teststatistik (6,118), die Freiheitsgrade (df (2)) sowie die Asymptotische Signifikanz (0,047) – die exakte Signifikanz spielt bei erwarteten Häufigkeiten ab 5 keine Rolle, steht hier also nur als Platzhalter.
Aus Teststatistik und Freiheitsgraden wird die Signifikanz ermittelt, was SPSS bequemerweise für uns berechnet. Diese ist nun dem Alphaniveau gegenüberzustellen.
Bei einem Alpha von 5% würde man aufgrund der darunter liegenden Signifikanz von p = 0,047 die Nullhypothese keines Unterschiedes verwerfen und die Alternativhypothese eines Unterschiedes annehmen.
Kritik zur strikten Entscheidung anhand des p-Wertes/Alpha-Niveaus vgl. Wasserstein (2016).
Der Chi²-Anpassungstest kommt hier zum Ergebnis, dass die Wohnsituation meiner Probanden nicht der unterstellten Verteilung (hier: Gleichverteilung) entspricht.
4.2 Output der neuen Dialogfelder
Hier ist bereits auf einen Blick erkennbar, was mit der Nullhypothese zu geschehen hat – sofern man das Alphaniveau auf 5% setzt. Die Nullhypothese wird zugunsten der Alternativhypothese verworfen. Der Chi²-Anpassungstest kommt logischerweise auch hier zum Ergebnis, dass die Wohnsituation meiner Probanden nicht der unterstellten Verteilung (hier: Gleichverteilung) entspricht.


Ein kleiner Zusatz der Auswertung über die neuen Dialogfelder ist die grafische Darstellung der erwarteten und beobachteten Häufigkeiten in einem gruppierten Säulendiagramm. Hübsch anzuschauen, allerdings finde ich es nicht gelungen die y-Achse nicht bei 0 beginnen zu lassen.


Hier bevorzuge ich dann doch eher die tabellarische Darstellung, die bei den klassischen Dialogfeldern ausgegeben wird.
5 Effektstärke Cohen’s ω
Bei Cohen (1988), S. 223 findet sich die Formel zur Berechnung von Cohen’s ω.
Die Wurzel aus dem Quotient von Chi-Quadrat-Wert/Teststatistik (6.118) und Stichprobengröße (51) – siehe oben:
![\[ \omega =\sqrt[]{\frac{\chi^2 }{N}} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-761cfab4c685ad0ecc3d131bd7a4edfa_l3.png "Rendered by QuickLaTeX.com")

![\[ \omega = \sqrt{\frac{6.118}{51}} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-2a9497b91d98dc6bda682ef6010e4130_l3.png "Rendered by QuickLaTeX.com")

![\[ \omega = 0.346 \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-6c9845af3b61b2240d07429a02887f20_l3.png "Rendered by QuickLaTeX.com")

6 Reporting
Das Berichten beschränkt sich auf die wesentlichen Dinge:
- Beobachtete und unterstellte Verteilung / Häufigkeiten
- Chi-Quadrat-Wert mit Freiheitsgraden (df): X²(df)
- p-Wert
- Effektstärke Cohen’s ω
- Einordnung von Cohen’s ω anhand ähnlicher Studien, fachspezifischen Grenzen oder Cohen (1992)
Beispielformulierung:
Die beobachtete Verteilung unterscheidet sich von der erwarteten Verteilung mit X²(2) = 6.118; p = 0.047;
ω = 0.346. Der Unterschied ist nach Cohen (1992) mittel.
7 Videotutorial
https://www.youtube.com/watch?v=sadQCk6tl6g/ https://www.youtube.com/watch?v=RLTlU917JVk/ https://www.youtube.com/watch?v=NPfBYNash6A/ https://www.youtube.com/watch?v=4I4hz7bUXCY/
8 Literatur
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences. Hillsdale, N.J: L. Erlbaum Associates.
- Cohen, J. (1992). Quantitative methods in psychology: A power primer. Psychol. Bull., 112, 155-159.
- Wasserstein, R. L., & Lazar, N. A. (2016). The ASA statement on p-values: context, process, and purpose. The American Statistician, 70(2), 129-133.