

1 Ziel des Chi-Quadrat (Chi²)-Anpassungstests in Excel
Der Chi²-Anpassungstest prüft eine kategoriale/nominale (wahlweise auch ordinale) Variable auf eine hypothetische bzw. theoretische Verteilung. Gleichverteilung ist hierbei der einfachste Fall – jede Ausprägung kommt (in etwa) gleich häufig vor. Andere Verteilungsannahmen können auch geprüft werden.
2 Voraussetzungen des Chi²-Anpassungstests in Excel
- Eine nominale skalierte Variable mit mindestens zwei Ausprägungen (ordinal funktioniert auch)
- Die Fälle sollten unabhängig voneinander sein
- Eine vermutete Verteilung, auf die getestet werden soll
- Alphaniveau, zu dem die Nullhypothese verworfen wird (typisch 0,05; 0,01 oder 0,001)
3 Durchführung des Chi²-Anpassungstests in Excel – ein Beispiel
Die Nullhypothese beim Chi²-Anpassungstests geht stets von Gleichheit der beobachteten und erwarteten Häufigkeiten aus.
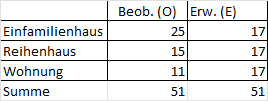
In meinem Datensatz möchte ich zunächst prüfen, ob die „Wohnsituation“ meiner Probanden gleichverteilt ist. Also kommt jede der drei Ausprägungen (Wohnung, Reihenhaus, Einfamilienhaus) über die Probanden hinweg gleich oft vor? In meinem Beispiel müssten bei 51 Probanden demnach jede der drei Ausprägungen 17 Mal vorkommen.
3.1 Häufigkeitstabelle für die beobachteten Häufigkeiten
In einem ersten Schritt empfiehlt es sich, die zu betrachtende Variable in eine Häufigkeitstabelle zu überführen, um die Anzahl der Ausprägungen zu ermitteln. Blogbeitrag zur Erstellung einer Häufigkeitstabelle.
Die hieraus resultierende Häufigkeitstabelle hier noch mal zur Vollständigkeit. Die Wohnung kommt 11 Mal vor, das Reihenhaus kommt 15 Mal vor und das Einfamilienhaus kommt 25 Mal vor und erhält die Spaltenüberschrift „Beob. (O)“. O steht hierbei für Observed.


3.2 Unterstellte Gleichverteilung
Für die erwartete Verteilung kann eine zusätzliche Spalte an die vorhandene Häufigkeitstabelle angehängt werden. Bei Gleichverteilung ist die Summe der beobachteten Häufigkeiten durch die Anzahl der Ausprägungen/Kategorien (hier 3) zu teilen. 51/3 = 17.
Die Spaltenüberschrift ist „Erw. (E)“. E steht hierbei für Expected.

3.1.1 Ermitteln des Chi²-Wertes
Die beobachteten und erwarteten Häufigkeiten, bzw. vielmehr deren Abweichungen, werden mit folgender Formel in eine Chi²-Teststatistik überführt:
Für jede Ausprägung wird die Abweichung quadriert und durch die erwartete Häufigkeit geteilt und anschließend aufsummiert.
![\[ chi ^{2}=\sum_{i=1}^{m}\left [ \left ( O-E \right )^2 /E\right] \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-baf18b64dc6f3f600418c01e4bc8594f_l3.png "Rendered by QuickLaTeX.com")

Zur besseren Nachvollziehbarkeit habe ich die Formeln in Excel sowie die Spalten- und Zeilenbeschriftungen eingeblendet und die Abbildung etwas vergrößert:
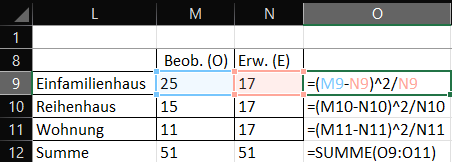

Das Ergebnis zeigt beim Einfamilienhaus die größte und beim Reihenhaus die kleinste Abweichung.
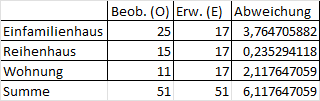

Die gebildete Summe über die Abweichungen führt im Ergebnis zum Chi²-Wert 6,1176.
Dieser muss nun noch in einen p-Wert überführt werden, damit die Nullhypothese verworfen oder bekräftigt werden kann.
3.1.2 Ermitteln des p-Wertes
In Excel kann der Chi-Quadrat-Wert recht einfach mit der CHIQU.VERT.RE()-Funktion in einen p-Wert überführt werden.
Hierzu bedarf es neben dem Chi-Quadrat-Wert noch den Freiheitsgraden.
Die Freiheitsgrade sind stets die Anzahl der Kategorien abzüglich 1.
Im Beispiel existieren 3 Kategorien. Demnach ist 3 – 1 = 2 Freiheitsgrade.
Diese 2 Freiheitsgrade werden neben dem Chi²-Wert von 6,1176 (in Zelle O12) in die CHIQU.VERT.RE()-Funktion gegeben:
=CHIQU.VERT.RE(O12;2)
Im Ergebnis beträgt der p-Wert p = 0,0469. Dies würde zur Verwerfung der Nullhypothese von Gleichheit zum Alphaniveau 0,05 führen. Demzufolge entspricht die vorliegende (beobachtete) Verteilung nicht der erwarteten (Gleich-)Verteilung.


3.3 Unterstellte andere Verteilung
Das Vorgehen bei anderen Verteilungen, die keine gleichen Häufigkeiten unterstellen, ist das Vorgehen analog zu oben.
- Erstellen einer Häufigkeitstabelle mit beobachteten Häufigkeiten (O)
- Festlegen der erwarteten Häufigkeiten (E)
- Ermittlung des Chi²-Wertes: Berechnung der Abweichungen und Summierung jener mit obiger Formel
- Überführung des Chi²-Wertes in einen p-Wert
- Hypothesenentscheidung anhand eines im Vorfeld festgelegten Alphaniveaus
Für erwartete Häufigkeiten von 21-mal Einfamilienhaus, 15-mal Reihenhaus und 15-mal Wohnung sieht dies wie folgt aus:
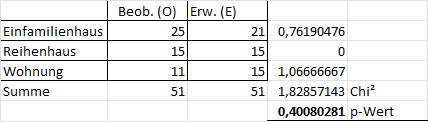
Die Nullhypothese kann in diesem Fall nicht verworfen werden. Die erwartete Verteilung bzw. die erwarteten Häufigkeiten entspricht in etwa der beobachteten Verteilung bzw. den beobachteten Häufigkeiten.
4 Effektstärke berechnen
Im Falle eines signifikanten Chi-Quadrat-Anpassungstests kann und sollte zur Einordnung des Effektes eines sog. Effektstärke berechnet werden. Hierzu eignet sich besonders Cohen’s ω, manchmal auch als Cohen’s w bezeichnet.
Die Formel zur Berechnung ist folgende und findet sich bei Cohen (1988) Statistical Power Analysis, S. 216:
![\[ \omega = \sqrt{\sum_{i=1}^{m} \frac{P_{Oi} - P_{Ei}} {P_{E_i}}} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-af35f25a8fb753711d4c8ab5ac75a184_l3.png "Rendered by QuickLaTeX.com")

![\[ P_{Oi} \textit{ sind die beobachteten relativen Haeufigkeiten} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-492f461634941eb83b93e4d61a1612a6_l3.png "Rendered by QuickLaTeX.com")

![\[ P_{Ei} \textit{ sind die erwarteten relativen Haeufigkeiten} \]](https://bjoernwalther.com/wp-content/ql-cache/quicklatex.com-73254c02751d7f3abc27b22851788780_l3.png "Rendered by QuickLaTeX.com")

Die beobachteten relativen Häufigkeiten können recht einfach berechnet werden. Die jeweilige absolute Anzahl der Beobachtungen des Merkmals wird hierzu durch die Gesamtzahl der Beobachtungen geteilt.
Beispiel: Das Einfamilienhaus kommt im Datensatz 25-Mal vor. Prozentual sind dies 25/51 = 0,4902, also 49,02%. Dies wird für alle Merkmalsausprägungen ausgerechnet.


Die erwarteten relativen Häufigkeiten müssen in der Regel nicht errechnet werden. Wenn doch, ist es dasselbe Vorgehen. Bei Gleichverteilung ist es noch einfacher.
Anschließend wird die quadrierte Differenz aus beobachteten und erwarteten relativen Häufigkeiten für jede Merkmalsausprägung gebildet. Ich habe dies hier als „Zähler“ bezeichnet:


Der Nenner ist jeweils wieder die erwartete relative Häufigkeit. Somit kann der Quotient für jedes Merkmal (hier: Wohnsituation) gebildet und anschließend aufsummiert werden.


Im Ergebnis ist die Summe der Quotienten im Beispielfall 0,11995. Hieraus muss letztendlich noch die Wurzel gezogen werden, welche 0,346 beträgt.


Cohen’s ω ist somit 0,346. Zur Einordnung dienen die fachspezifischen Grenzen, alternativ kann Cohen (1992), S. 157 herangezogen werden:
- ab 0,1 schwacher Effekt
- ab 0,3 mittlere Effekt
- ab 0,5 starker Effekt
Im Beispiel liegt ein mittlere Unterschied vor.
5 Reporting
Zu berichten sind typischerweise der Chi-Quadrat-Wert samt Freiheitsgraden (siehe oben für deren Ermittlung), der p-Wert sowie im Falle eines signifikanten Testergebnisses auch die Effektstärke Cohen’s ω samt Einordnung.
Beispielformulierung:
„Die beobachtete Verteilung unterscheidet sich von der erwarteten Verteilung mit X²(2) = 6,118; p = 0,047; ω = 0.346.
Der Unterschied ist nach Cohen (1992) mittel.“
6 Videotutorial
https://www.youtube.com/watch?v=_Dc3ZHTH958 /https://www.youtube.com/watch?v=auIacFKmn5E /
Literatur
- Effektstärkengrenzen: Cohen, J. (1988): Statistical Power Analysis for the Behavioral Sciences. bzw.
- Cohen, J. (1992). A power primer. Psychological bulletin, 112(1), 155-159.